Apache Kafka与Zookeeper分布式消息系统部署实战指南
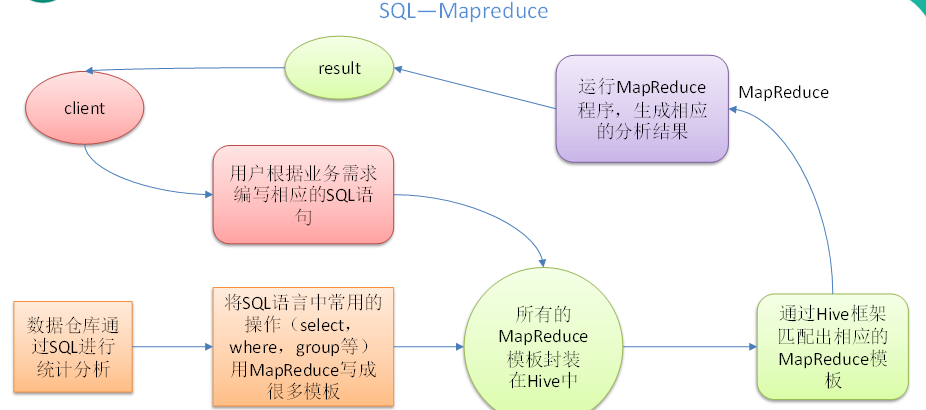
1. kafka
工作原理:
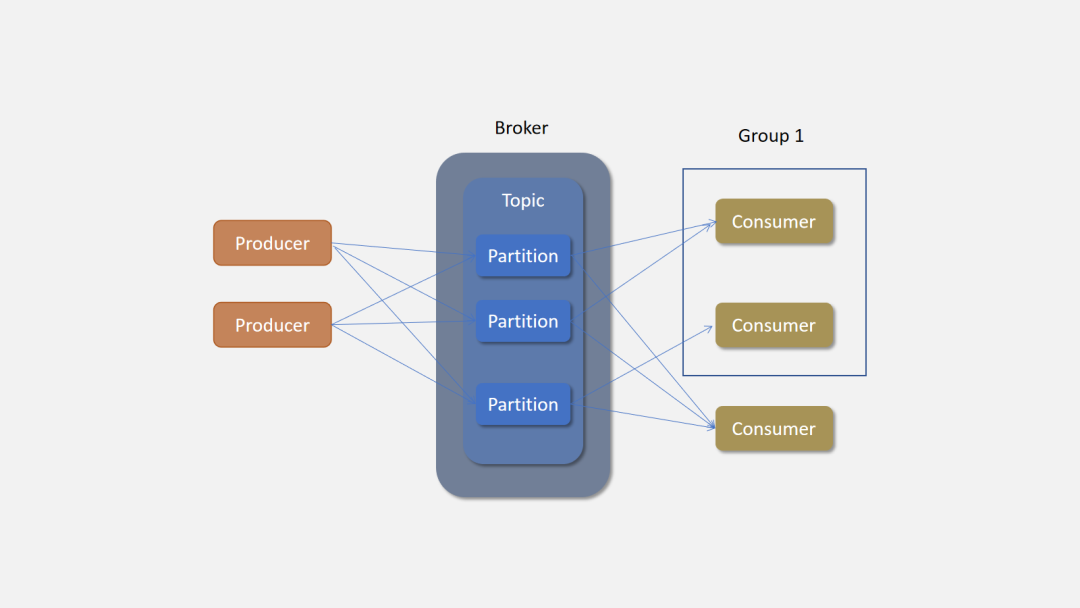
Producer: 生产者,发送消息的一方。生产者负责创建消息,然后将其发送到 Kafka。
Consumer: 消费者,接受消息的一方。消费者连接到 Kafka 上并接收消息,进而进行相应的业务逻辑处理。
Consumer Group: 一个消费者组可以包含一个或多个消费者。使用多分区 + 多消费者方式可以极大提高数据下游的处理速度,同一消费组中的消费者不会重复消费消息,同样的,不同消费组中的消费者消息消息时互不影响。Kafka 就是通过消费组的方式来实现消息 P2P 模式和广播模式。
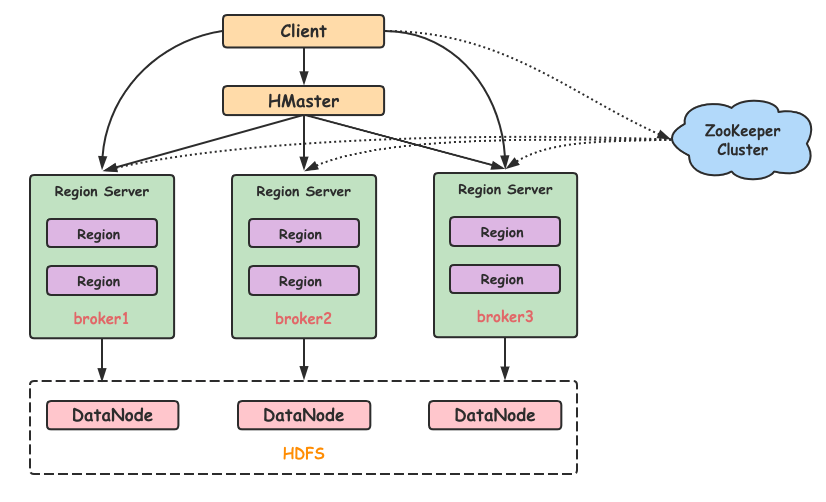
Broker: 服务代理节点。Broker 是 Kafka 的服务节点,即 Kafka 的服务器。
Topic: Kafka 中的消息以 Topic 为单位进行划分,生产者将消息发送到特定的 Topic,而消费者负责订阅 Topic 的消息并进行消费。
Partition: Topic 是一个逻辑的概念,它可以细分为多个分区,每个分区只属于单个主题。同一个主题下不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。
Offset: offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka 保证的是分区有序性而不是主题有序性。
Replication: 副本,是 Kafka 保证数据高可用的方式,Kafka 同一 Partition 的数据可以在多 Broker 上存在多个副本,通常只有主副本对外提供读写服务,当主副本所在 broker 崩溃或发生网络异常,Kafka 会在 Controller 的管理下会重新选择新的 Leader 副本对外提供读写服务。
Record: 实际写入 Kafka 中并可以被读取的消息记录。每个 record 包含了 key、value 和 timestamp。
1.1生产者-消费者
生产者–消费者是一种设计模式,生产者和消费者之间通过添加一个中间组件来达到解耦。生产者向中间组件生成数据,消费者消费数据。
就像 65 哥读书时给小芳写情书,这里 65 哥就是生产者,情书就是消息,小芳就是消费者。但有时候小芳不在,或者比较忙,65 哥也比较害羞,不敢直接将情书塞小芳手里,于是将情书塞在小芳抽屉中。所以抽屉就是这个中间组件。
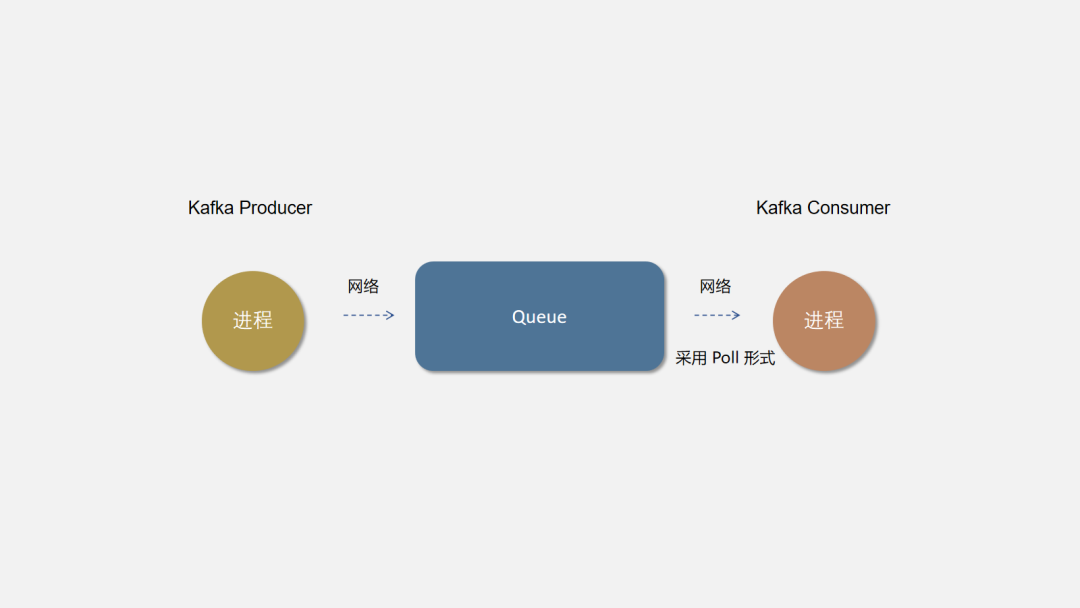
在程序中我们通常使用Queue来作为这个中间组件。可以使用多线程向队列中写入数据,另外的消费者线程依次读取队列中的数据进行消费。模型如下图所示:
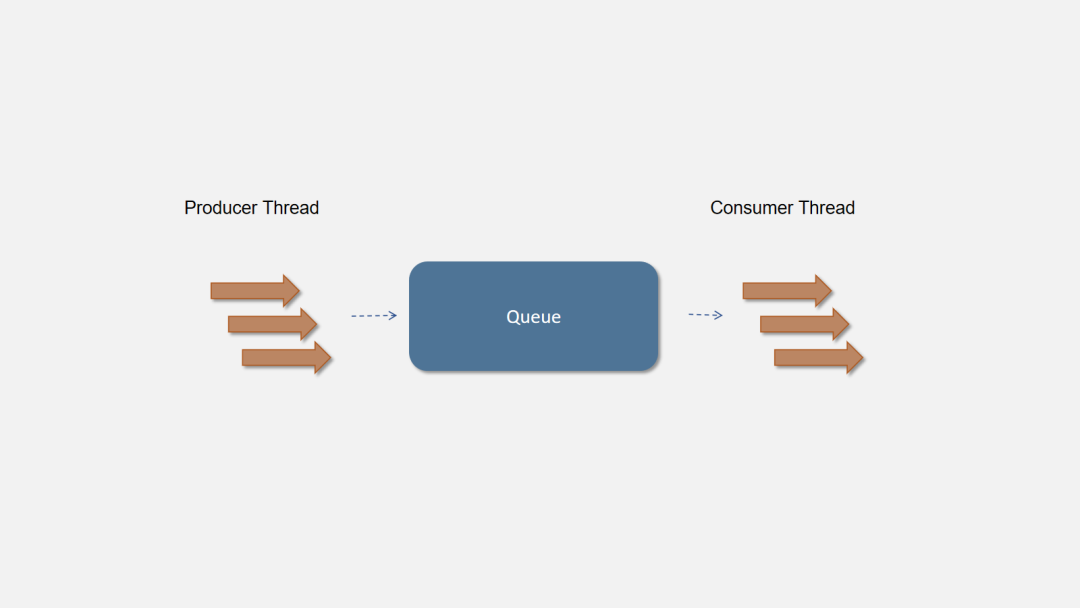
生产者–消费者模式通过添加一个中间层,不仅可以解耦生产者和消费者,使其易于扩展,还可以异步化调用、缓冲消息等。
1.1.3 分布式队列
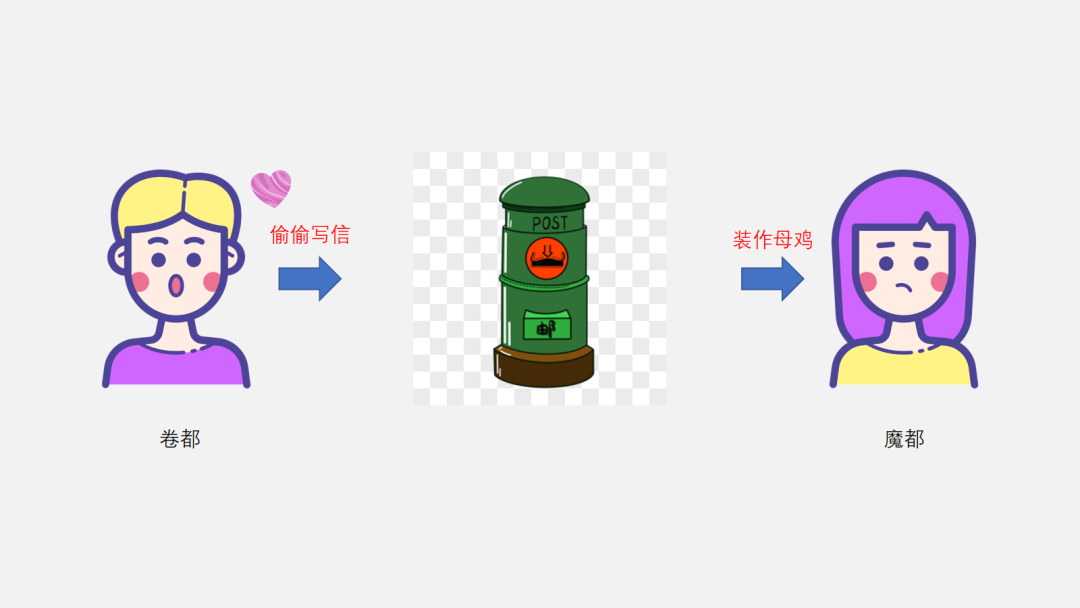
后来 65 哥和小芳异地了,65 哥在卷都奋斗,小芳在魔都逛街。于是只能通过邮局寄暧昧信了。这样 65 哥、邮局和小芳就成了分布式的了。65 哥将信件发给邮局,小芳从邮局拿到 65 哥写的信,再回去慢慢看。
Kafka 的消息生产者就是Producer,上游消费者进程添加 Kafka Client 创建 Kafka Producer,向 Broker 发送消息,Broker 是集群部署在远程服务器上的 Kafka Server 进程,下游消费者进程引入 Kafka Consumer API 持续消费队列中消息。
因为 Kafka Consumer 使用 Poll 的模式,需要 Consumer 主动拉去消息。所有小芳只能定期去邮局拿信件了(呃,果然主动权都在小芳手上啊)。
1.1.4 主题
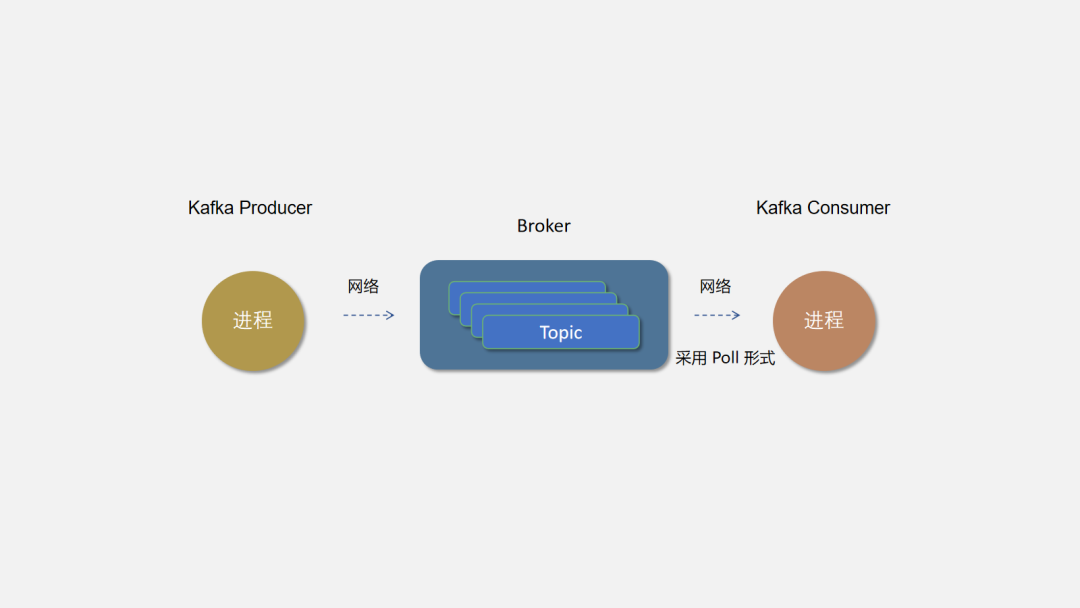
邮局不能只为 65 哥服务,虽然 65 哥一天写好几封信。但也无法挽回邮局的损失。所以邮局是可以供任何人寄信。只需要寄信人写好地址(主题),邮局建有两地的通道就可以发收信件了。
Kafka 的 Topic 才相当于一个队列,Broker 是所有队列部署的机器。可以按业务创建不同的 Topic,Producer 向所属业务的 Topic 发送消息,相应的 Consumer 可以消费并处理消息。
1.1.5 分区
由于 65 哥写的信太多,一个邮局已经无法满足 65 哥的需求,邮政公司只能多建几个邮局了,65 哥将信件按私密度分类(分区策略),从不同的邮局寄送。
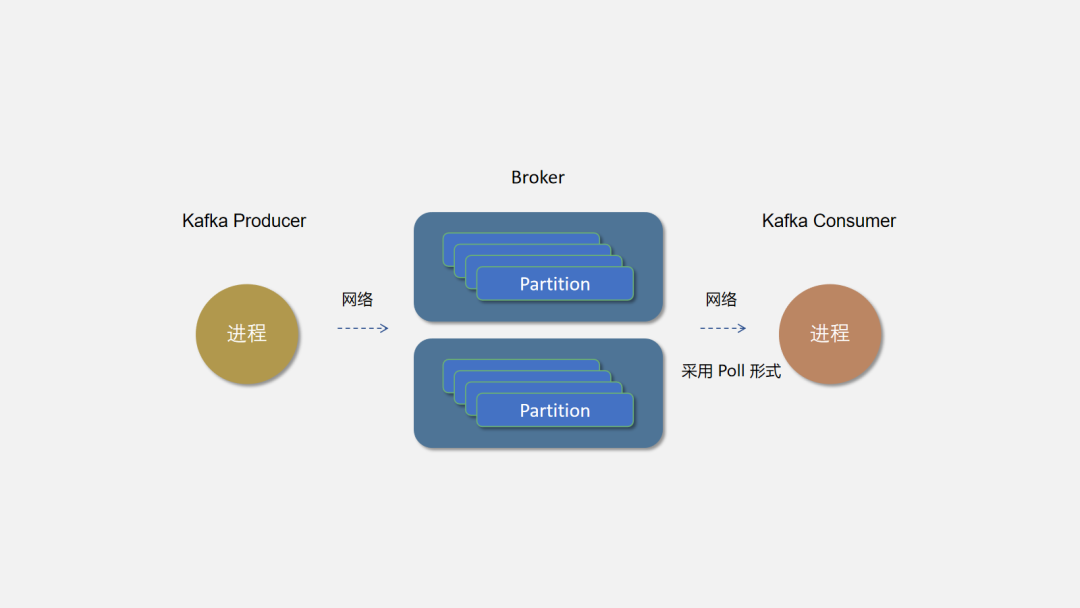
同一个 Topic 可以创建多个分区。理论上分区越多并发度越高,Kafka 会根据分区策略将分区尽可能均衡的分布在不同的 Broker 节点上,以避免消息倾斜,不同的 Broker 负载差异太大。分区也不是越多越好哦,毕竟太多邮政公司也管理不过来
1.1.6 副本
为防止由于邮局的问题,比如交通断啦,邮车没油啦。导致 65 哥的暧昧信无法寄到小芳手上,使得 65 哥晚上远程跪键盘。邮局决定将 65 哥的信件复制几份发到多个正常的邮局,这样只要有一个邮局还在,小芳就可以收到 65 哥的信了。
Kafka 采用分区副本的方式来保证数据的高可用,每个分区都将建立指定数量的副本数,kakfa 保证同一分区副本尽量分布在不同的 Broker 节点上,以防止 Broker 宕机导致所有副本不可用。Kafka 会为分区的多个副本选举一个作为主副本(Leader),主副本对外提供读写服务,从副本(Follower)实时同步 Leader 的数据。

1.1.7 多消费者
哎,65 哥的信件满天飞,小芳天天跑邮局,还要一一拆开看,65 哥写的信又臭又长,让小芳忙得满身大汗。于是小芳啪的一下,很快啊,变出多个分身去不同的邮局取信,这样小芳终于可以挤出额外的时间逛街了。
1.1.8 广播消息
邮局最近提供了定制明信片业务,每个人都可以设计明信片,同一个身份只能领取一种明信片。65 哥设计了一堆,广播给所有漂亮的小妹妹都可以来领取,美女啪变出的分身也可以来领取,但是同一个身份的多个分身只能取一种明信片。
Kafka 通过 Consumer Group 来实现广播模式消息订阅,即不同 group 下的 consumer 可以重复消费消息,相互不影响,同一个 group 下的 consumer 构成一个整体。
最后我们完成了 Kafka 的整体架构,如下:
2. Zookeeper
Zookeeper 是一个成熟的分布式协调服务,它可以为分布式服务提供分布式配置服务、同步服务和命名注册等能力.。对于任何分布式系统,都需要一种协调任务的方法。Kafka 是使用 ZooKeeper 而构建的分布式系统。但是也有一些其他技术(例如 Elasticsearch 和 MongoDB)具有其自己的内置任务协调机制。
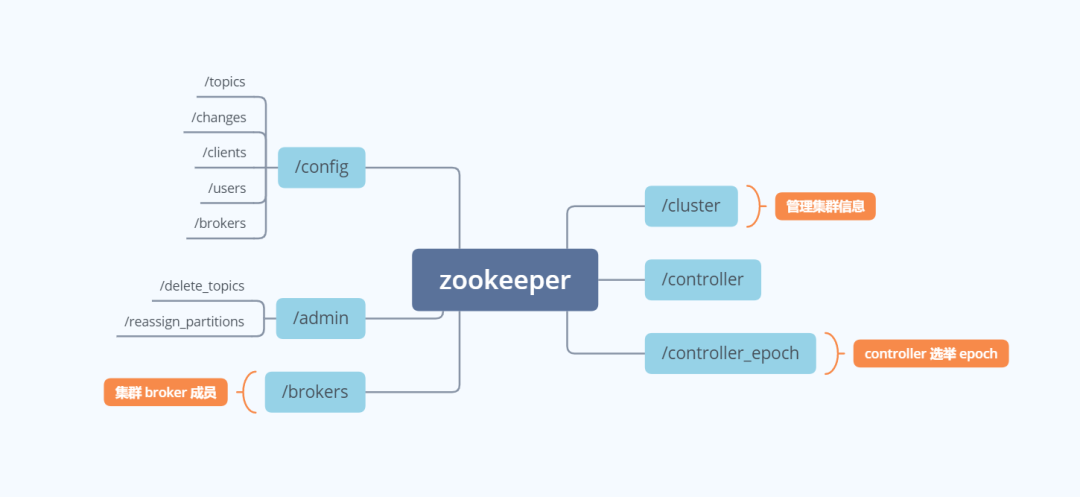
Kafka 将 Broker、Topic 和 Partition 的元数据信息存储在 Zookeeper 上。通过在 Zookeeper 上建立相应的数据节点,并监听节点的变化,Kafka 使用 Zookeeper 完成以下功能:
- Kafka Controller 的 Leader 选举
- Kafka 集群成员管理
- Topic 配置管理
- 分区副本管理
我们看一看 Zookeeper 下 Kafka 创建的节点,即可一目了然的看出这些相关的功能。
实验环境
| 容器系统 | 容器主机名 | 容器ip | 容器用户名 |
|---|---|---|---|
| centos7 | master | 192.168.1.10 | root |
| centos7 | slave1 | 192.168.1.20 | root |
| centos7 | slave2 | 192.168.1.30 | root |
前提:已配置好java环境
3. zookeeper分布式部署
3.1 解压所需压缩包并重命名
[root@master ~]# tar -zxvf /opt/software/zookeeper-3.4.6.tar.gz -C /opt/module/
[root@master ~]# mv /opt/module/zookeeper-3.4.6/ /opt/module/zookeeper
3.2 配置环境变量
所有节点添加
添加环境变量:
#zookeeper
export ZK_HOME=/opt/module/zookeeper
export PATH=PATH:ZK_HOME/bin
刷新生效:
source /etc/profile
3.3 配置zoo.cfg文件
创建数据目录和日志目录
[root@master ~]# mkdir /opt/module/zookeeper/{data,logs}
[root@master ~]# cp /opt/module/zookeeper/conf/zoo_sample.cfg /opt/module/zookeeper/conf/zoo.cfg
[root@master ~]# vi /opt/module/zookeeper/conf/zoo.cfg
配置内容如下:
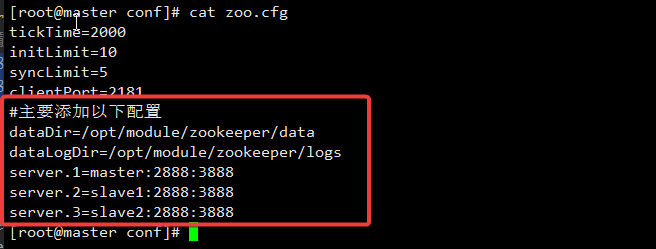
[root@master conf]# cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/module/zookeeper/data
dataLogDir=/opt/module/zookeeper/logs
clientPort=2181
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
配置详解:
[root@kafka1 opt]# grep -Ev "#|^$" /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/module/zookeeper/data
dataLogDir=/opt/module/zookeeper/logs
clientPort=2181
maxClientCnxns=4096 #(可选)
autopurge.snapRetainCount=128 # /opt/zookeeper里保存快照的最大数量(可选)
autopurge.purgeInterval=1 # 几小时清理一次(可选)
# 可以用主机名,因为设置了映射
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
配置参数解读:
server.A=B:C:D
A是一个数字,表示这个是第几号服务器。myid中的编号就是这个值。zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址。
C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
D是万一集群中的leader服务器挂了,需要一个端口来重新进行选举,选举一个新的leader,而这个端口就是用来执行选举时服务器相互通信的端口。
结果:
3.4 配置myid文件
[root@master zookeeper]# echo 1 > $ZK_HOME/data/myid
3.5 分发文件给子节点并分别修改myid文件
:warning:注意:如果子节点没有配置环境变量,也要一同分发
分发:
[root@master ~]# scp -r /opt/module/zookeeper/ root@slave1:/opt/module/
[root@master ~]# scp -r /opt/module/zookeeper/ root@slave2:/opt/module/
修改myid文件:
slave1:
[root@slave1 ~]# echo 2 > /opt/module/zookeeper/data/myid
[root@slave1 ~]# echo 2 > $ZK_HOME/data/myid
slave2:
[root@slave2 ~]# echo 3 > /opt/module/zookeeper/data/myid
[root@slave2 ~]# echo 3 > $ZK_HOME/data/myid
3.6 编写脚本启动zk服务(可选)
[root@master ~]# vi /opt/module/zookeeper/bin/zk.sh
[root@master ~]# vi $ZK_HOME/bin/zk.sh
脚本内容如下:
#!/bin/bash
case 1 in
"start")
echo "=======启动zookeeper集群=============="
for i in master slave1 slave2;do
echo "---------------启动i-------------"
ssh i "source /etc/profile;{ZK_HOME}/bin/zkServer.sh start"
done
;;
"stop")
echo "========关闭zookeeper集群============"
for i in master slave1 slave2;do
echo "---------------关闭i-------------"
sshi "source /etc/profile;{ZK_HOME}/bin/zkServer.sh stop"
done
;;
"status")
echo "=======查看zookeeper集群节点状态========="
for i in master slave1 slave2;do
echo "---------------查看i-------------"
ssh i "source /etc/profile;{ZK_HOME}/bin/zkServer.sh status"
done
;;
*)
echo "请输入start或stop或status!!!"
;;
esac
添加可执行权限
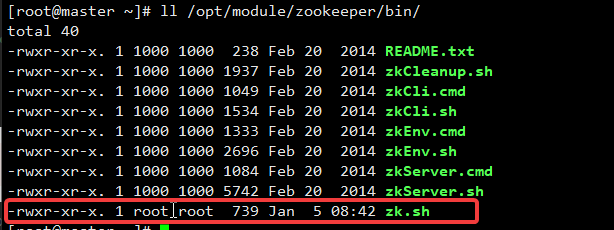
[root@master ~]# chmod +x $ZK_HOME/bin/zk.sh
查看是否添加成功:
[root@master ~]# ll /opt/module/zookeeper/bin/
3.7 启动zk服务
方法1:绝对路径启动服务
所有节点启动:
/opt/module/zookeeper/bin/zkServer.sh start
查看启动状态:
/opt/module/zookeeper/bin/zkServer.sh status
master:

slave1:

slave2:

方法2:脚本一键启动服务
启动:
[root@master ~]# zk.sh start
结果:
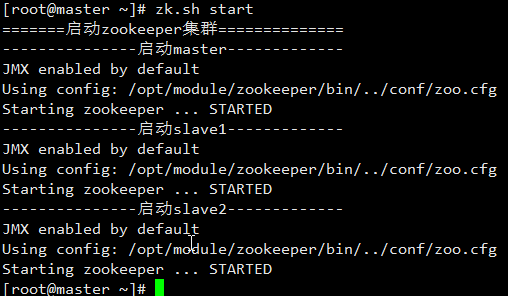
查看服务状态:
[root@master ~]# zk.sh status
结果:
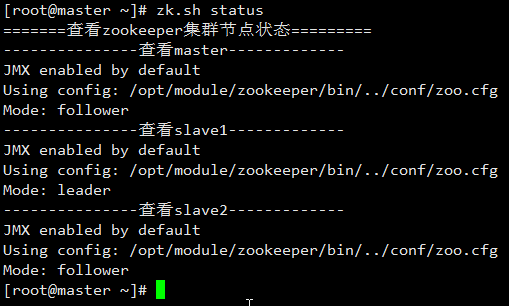
zookeeper集群部署完成
4. kafka分布式部署
4.1解压所需压缩包并重命名
[root@master ~]# tar -zxf /opt/software/kafka_2.12-2.4.1.tgz -C /opt/module/
[root@master ~]# mv /opt/module/kafka_2.12-2.4.1/ /opt/module/kafka
4.2 配置环境变量
所有节点添加
添加环境变量:
刷新生效:
source /etc/profile
查看kafka版本号:
kafka-topics.sh --version
结果:

4.3 配置server.properties文件
添加内容如下:
注意删除后面的备注
[root@master config]# grep -Ev "^$|^#" server.properties
broker.id=0 # 节点id要唯一
listeners=PLAINTEXT://master:9092 # 改成本机ip,如果配置好主机映射即可使用主机名
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/module/kafka/kafka-logs # 储存日志文件
num.partitions=1 #这个参数用于设置新创建的topic有多少个分区,可以根据消费者实际情况配置
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168 #这个参数用于配置kafka中消息保存的时间,还支持log.retention.minutes和log.retention.ms配置项
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=master:2181,slave1:2181,slave2:2181 # 所有节点的ip或者映射
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
主要修改添加如下,剩下的默认就好:
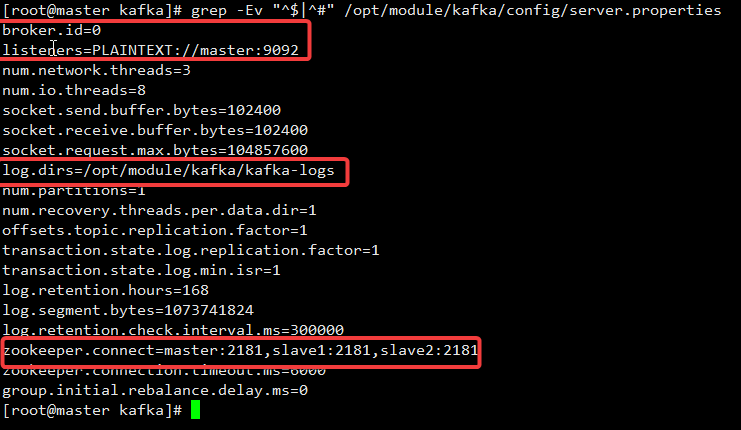
4.4 分发文件给子节点并分别修改broker.id 和 listener ip
分发:
[root@master module]# scp -r /opt/module/kafka/ root@slave1:/opt/module/
[root@master module]# scp -r /opt/module/kafka/ root@slave2:/opt/module/
修改子节点配置:
vi /opt/module/kafka/config/server.properties
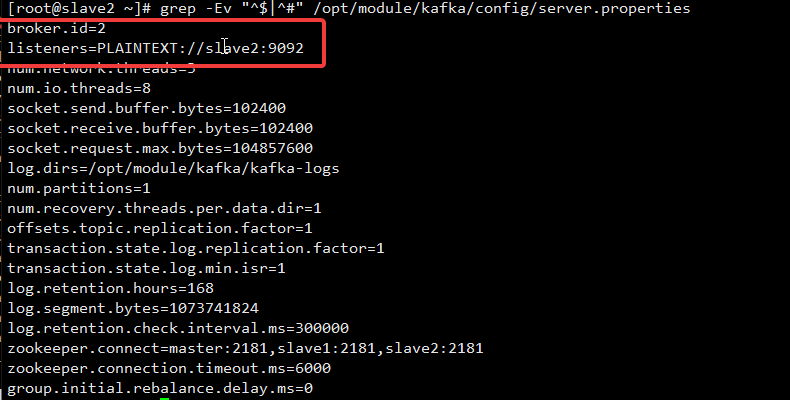
修改的部分如下:
slave1:
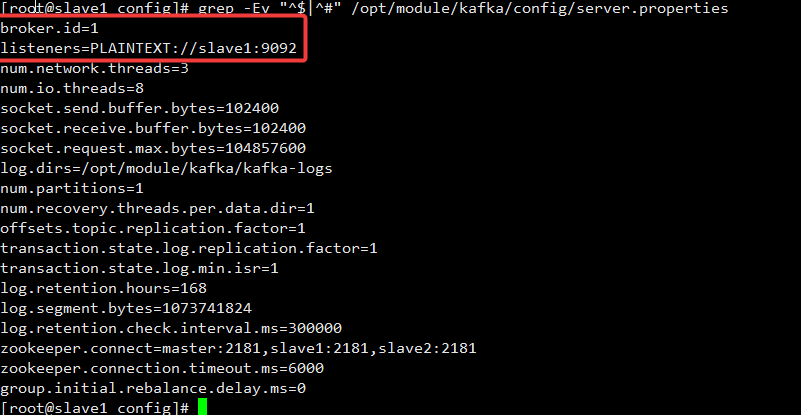
slave2:
4.5 编写启动脚本(可选)
vi /opt/module/kafka/bin/kafka.sh
vi KAFKA_HOME/bin/kafka.sh
chmod +x /opt/module/kafka/bin/kafka.sh
chmod +xKAFKA_HOME/bin/kafka.sh
脚本内容如下:
#!/bin/bash
case 1 in
"start")
echo "=======启动kafka集群=============="
for i in master slave1 slave2;do
echo "---------------启动i-------------"
ssh i "source /etc/profile;{KAFKA_HOME}/bin/kafka-server-start.sh -daemon KAFKA_HOME/config/server.properties"
if [? -eq 0 ];then
echo -e '\033[32m>>i kafka服务启动成功!! \033[0m'
fi
done
;;
"stop")
echo "========关闭kafka集群============"
for i in master slave1 slave2;do
echo "---------------关闭i-------------"
ssh i "source /etc/profile;{KAFKA_HOME}/bin/kafka-server-stop.sh"
if [ ? -eq 0 ];then
echo -e '\033[32m>>i kafka服务关闭成功!! \033[0m'
fi
done
;;
*)
echo "请输入start或stop!!!"
;;
esac
4.6 启动kafka服务
方式1:绝对路径启动服务
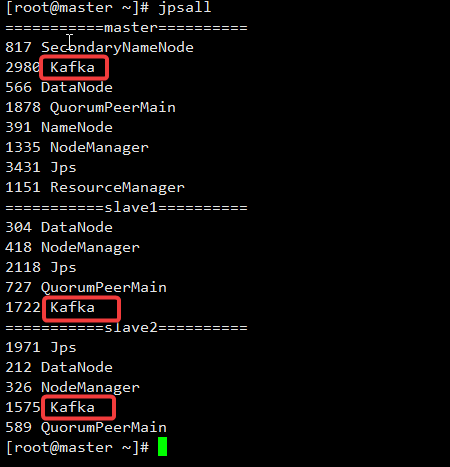
所有节点启动:
kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
结果:
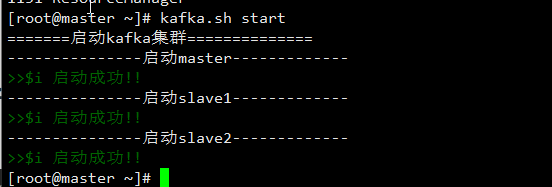
方式2:脚本一键启动
[root@master ~]# kafka.sh start
结果:
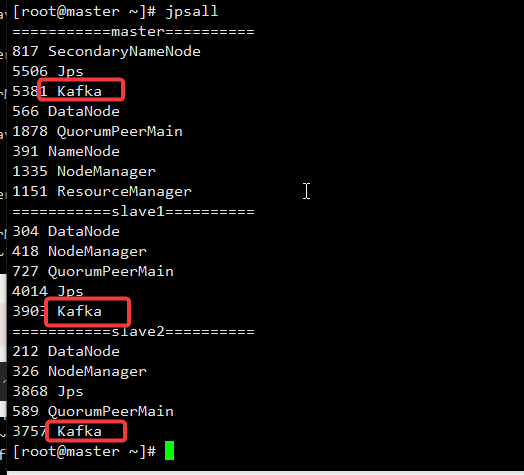
查看进程:
部署完成!!!
5. kafka集群基本命令操作
kefka提供了多个命令用于查看、创建、修改、删除topic信息,也可以通过命令测试如何生产消息、消费消息等,这些命令位于kafka安装目录的bin目录下,这里是/usr/local/kafka/bin。登录任意一台kafka集群节点,切换到此目录下,即可进行命令操作。下面列举kafka的一些常用命令的使用方法。
创建主题与测试
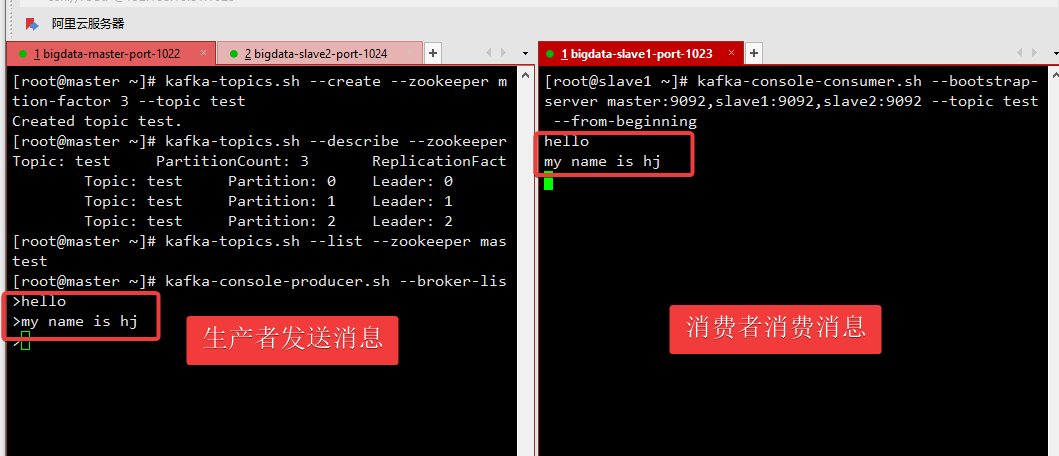
[root@master ~]# kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181 --partitions 3 --replication-factor 3 --topic test
Created topic test.
# 验证topic
[root@master ~]# kafka-topics.sh --describe --zookeeper master:2181,slave1:2181,slave2:2181 --topic test
Topic: test PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: test Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: test Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
# 获取所有topic(查看已有的topic)
[root@kafka1 config]# kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181
test
参数解释:
--create:表示你要创建一个新的 Kafka 主题。--zookeeper master:2181,slave1:2181,slave2:2181:指定了 Zookeeper 的连接字符串。Zookeeper 用于管理和协调 Kafka 经纪人。--partitions 3:设置主题的分区数。在这里,主题将有 3 个分区。--replication-factor 3:定义主题的复制因子。每个分区将在不同的 Kafka 经纪人上具有三个副本,以实现容错。--topic test:指定 Kafka 主题的名称,在这里是 “test”。
生产消息
[root@master ~]# kafka-console-producer.sh --broker-list master:9092,slave1:9092,slave2:9092 --topic test
>this is a test
消费消息
[root@slave1 ~]# kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092 --topic test --from-beginning
this is a test
# 在1号即发消息,这里能收到消息
删除消息
[root@master ~]# kafka-topics.sh --zookeeper master:2181,slave1:2181,slave2:2181 --delete --topic test
kafka可视化工具(略)
官网:https://www.kafkatool.com/download.html
文档参考:https://www.freesion.com/article/72661130783/
博客:
官网:
ubuntu版本直接拉取脚本运行安装即可:
wget https://www.kafkatool.com/download2/offsetexplorer.sh
sudo sh offsetexplorer.sh
完成!!