Hadoop完全分布式与HA高可用部署指南
1.Hadoop 概述
1.1 Hadoop 是什么
(1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构
(2)主要解决海量数据的存储和海量数据的分析计算问题
(3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈
1.2 Hadoop 优势
(1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
(2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
(3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
(4)高容错性:能够自动将失败的任务重新分配。
1.3 Hadoop 组成(面试重点)
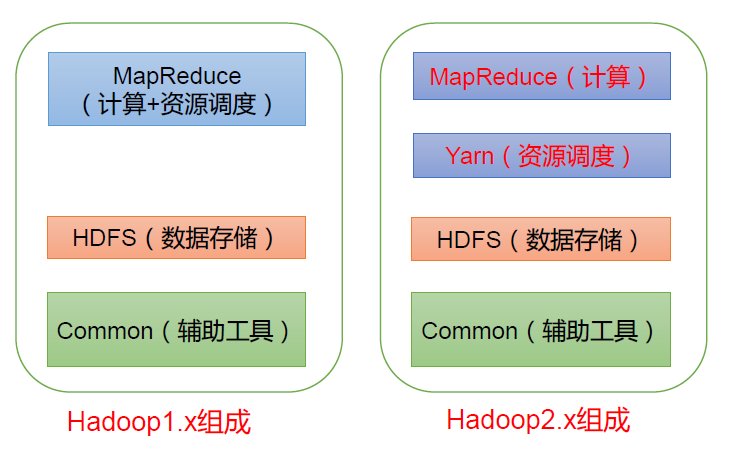
在Hadoop1.x 时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。 在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce 只负责运算。 Hadoop3.x在组成上没有变化。
1.3.1 HDFS 架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
(1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
(2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
(3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
1.3.2 YARN 架构概述
Yet Another Resource Negotiator 简称YARN ,另一种资源协调者,是Hadoop 的资源管理器。
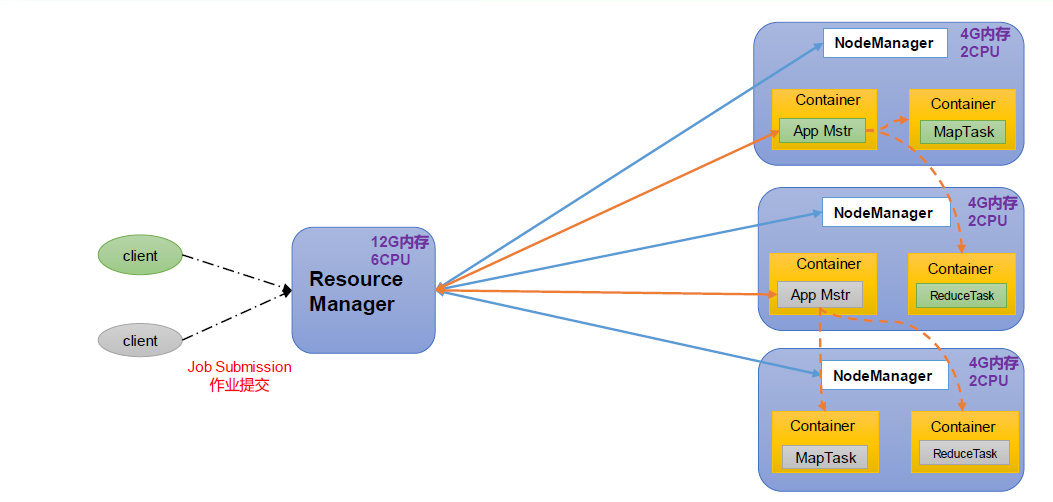
ResourceManager(RM):整个集群资源(内存、CPU等)的管理者
NodeManager(NM):单个节点服务器资源的管理者。
ApplicationMaster(AM):单个任务运行的管理者。
Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
说明:
(1)客户端可以有多个
(2)集群上可以运行多个ApplicationMaster
(3)每个NodeManager上可以有多个Container
1.3.3 MapReduce 架构概述
MapReduce 将计算过程分为两个阶段:Map 和Reduce 1)Map 阶段并行处理输入数据 2)Reduce 阶段对Map 结果进行汇总
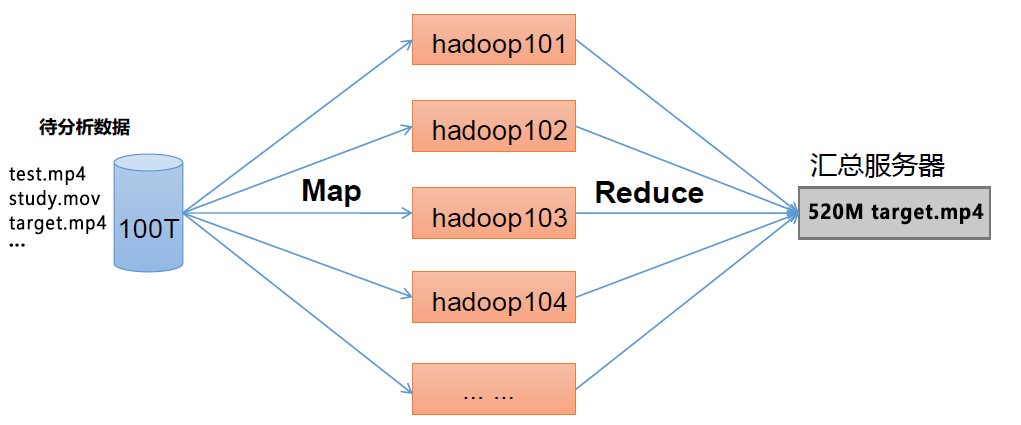
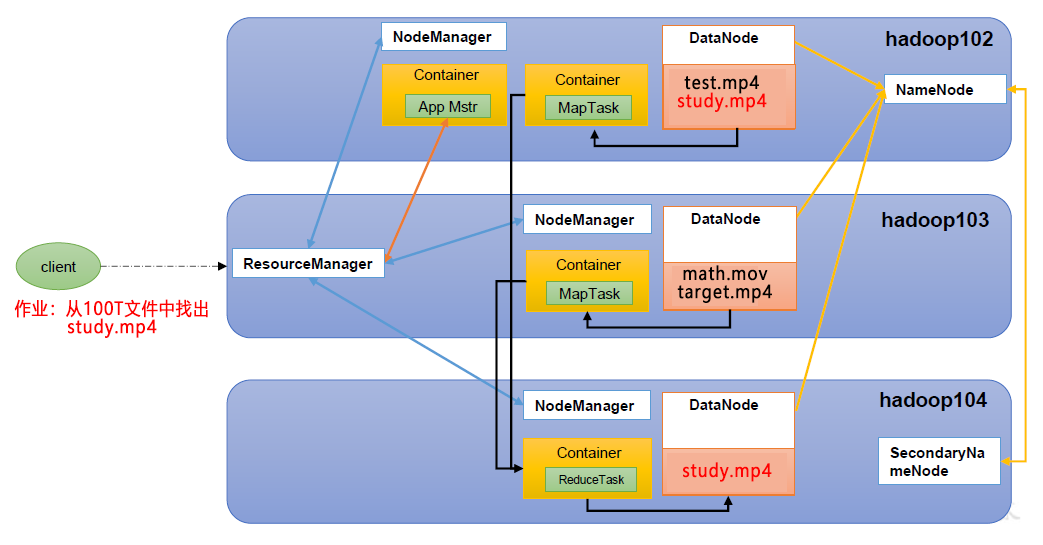
1.3.4 HDFS、YARN、MapReduce 三者关系
如图所示:
1.3.5 大数据技术生态体系
如图所示: 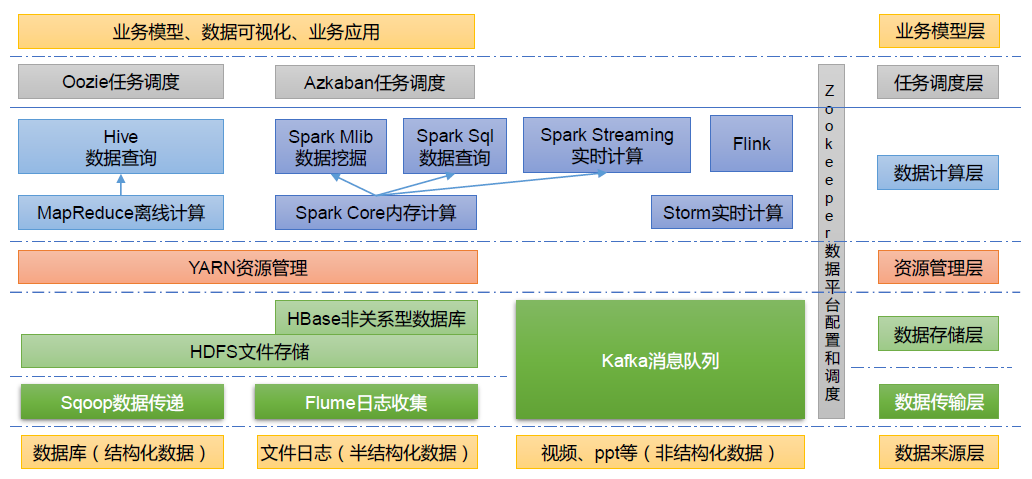
图中涉及的技术名词解释如下:
(1)Sqoop:Sqoop 是一款开源的工具,主要用于在Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop 的HDFS 中,也可以将HDFS 的数据导进到关系型数据库中。
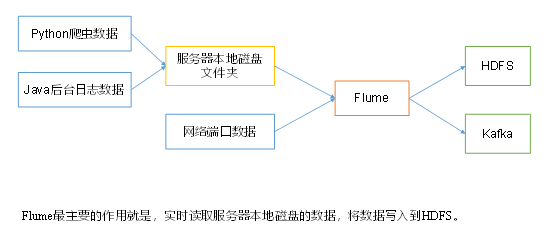
(2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据。 (3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统。
(4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于Hadoop 上存储的大数据进行计算。
(5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
(6)Oozie:Oozie 是一个管理Hadoop 作业(job)的工作流程调度管理系统。
(7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
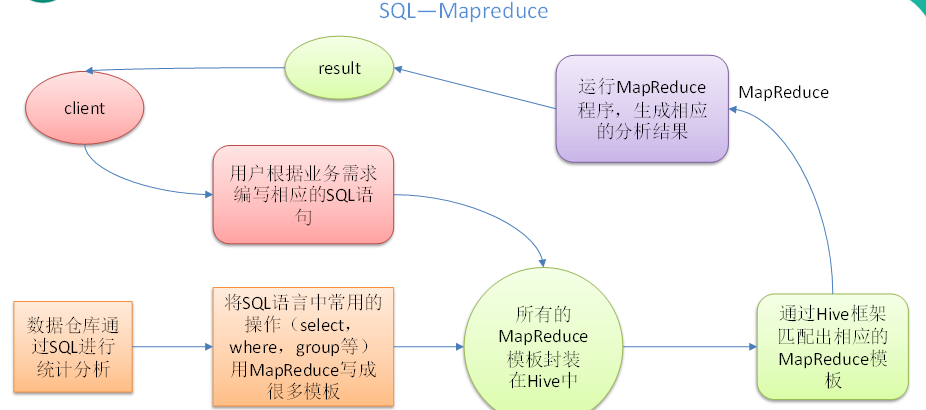
(8)Hive:Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL 查询功能,可以将SQL 语句转换为MapReduce 任务进行运行。其优点是学习成本低,可以通过类SQL 语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce 应用,十分适合数据仓库的统计分析。
(9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
1.3.6 推荐系统框架图
推荐系统项目框架
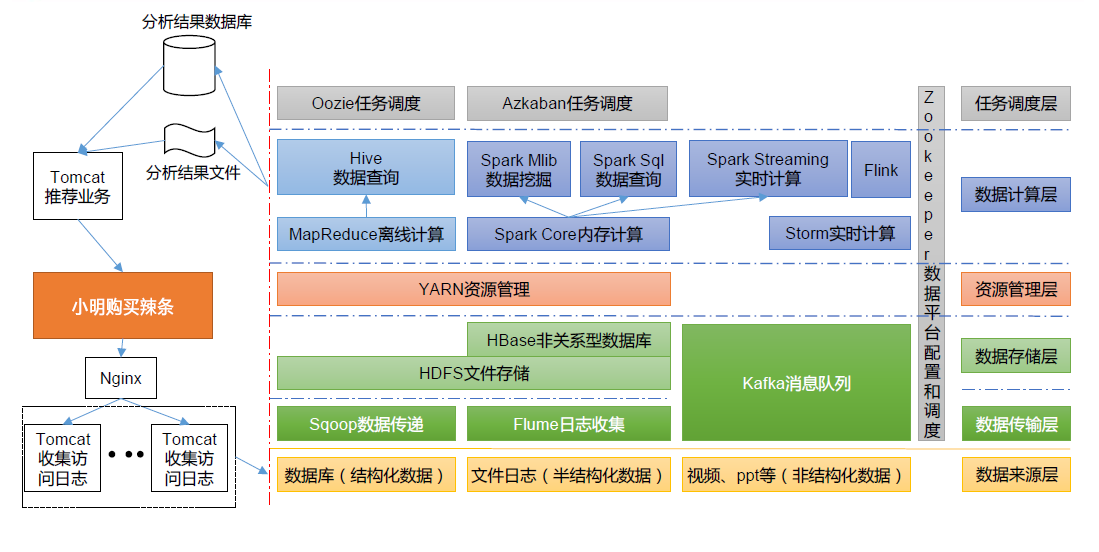
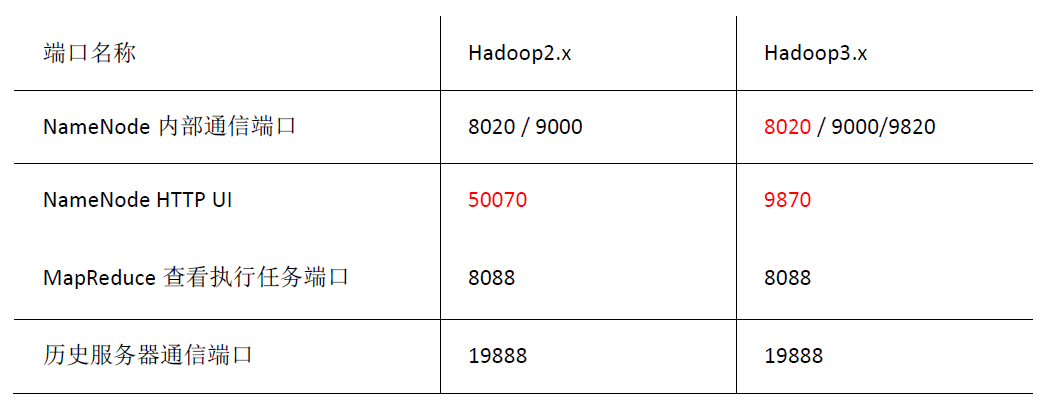
1.3.7 常用端口号说明
2. Hadoop 完全分部署运行环境搭建
环境说明:
| 容器 | 容器ip |
|---|---|
| master | 192.168.1.10 |
| slave1 | 192.168.1.20 |
| slave2 | 192.168.1.30 |
2.1 配置主机名
hostnamectl set-hostname master && bash
hostnamectl set-hostname slave1 && bash
hostnamectl set-hostname slave2 && bash
2.2 修改hosts,添加映射,关闭防火墙
所有节点执行
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.1.10 master
192.168.1.20 slave1
192.168.1.30 slave2
systemctl stop firewalld
systemctl disable firewalld
2.3 设置三台主机的免密登录
2.3.1 生成免密公钥
[root@master ~]# ssh-keygen -t rsa #然后一直回车
或者
[root@master ~]# ssh-keygen -f ~/.ssh/id_rsa -P '' #免回车
2.3.2 复制公钥到服务器
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2

(另外两个节点也是如此操作,这里就不演示了)
2.4 JDK配置
解压文件到相应的位置:
[root@master ~]# tar -zxvf /opt/software/jdk-8u162-linux-x64.tar.gz -C /opt/module/
[root@master ~]# cd /opt/module/ #进入解压目录,可以给解压后的文件改个名字,方便记忆
[root@master module]# mv jdk1.8.0_162/ jdk
设置jdk环境变量:
[root@master module]# vi /etc/profile
在末尾添加如下配置:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH=PATH:JAVA_HOME/bin:$JAVA_HOME/jre/bin
刷新环境变量:
[root@master module]# source /etc/profile
配置完后即可查看jdk版本号:
[root@master module]# java -version

分发JDK和环境变量到两个副节点:
[root@master module]# scp /etc/profile root@slave1:/etc/profile
[root@master module]# scp /etc/profile root@slave2:/etc/profile
[root@master module]# scp -rq jdk/ root@slave1:/opt/module/
[root@master module]# scp -rq jdk/ root@slave2:/opt/module/

分发到两个副节点后,刷新环境变量,查看JAVA版本:
slave1节点:

slave2节点:

基础环境搭建完成!!
添加jpsall脚本(可选)
vi JAVA_HOME/bin/jpsall
chmod +xJAVA_HOME/bin/jpsall
脚本内容如下:
#!/bin/bash
for hostname in master slave1 slave2
do
echo ===========hostname==========
sshhostname ". /etc/profile; jps"
done
2.5 Hadoop环境搭建
前提:已完成3个节点的免密登录,jdk配置
2.5.1 解压包到相应位置:
[root@master module]# tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
[root@master module]# mv hadoop-3.1.3/ hadoop #改一下名字,方便记忆
2.5.2 添加hadoop环境变量
[root@master module]# vi /etc/profile
在末尾添加以下内容:
#HADOOP
export HADOOP_HOME=/opt/module/hadoop
export PATH=PATH:HADOOP_HOME/bin:HADOOP_HOME/sbin
export HADOOP_CLASSPATH=`HADOOP_HOME/bin/hadoop classpath`
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#备注:3.0后的版本需要指定服务用户
:wq 保存退出后,刷新环境变量:
[root@master module]# source /etc/profile
配置好后,即可直接查看hadoop 版本号
[root@master module]# hadoop version

2.6 修改6个主配置文件
- :one: core.site.xml
- :two: hdfs-site.xml
- :three: mapred-site.xml
- :four:yarn-site.xml
- :five: hadoop-env.sh
- :six: workers
配置参考官方文档
目录:
\hadoop-3.1.3\share\doc\hadoop
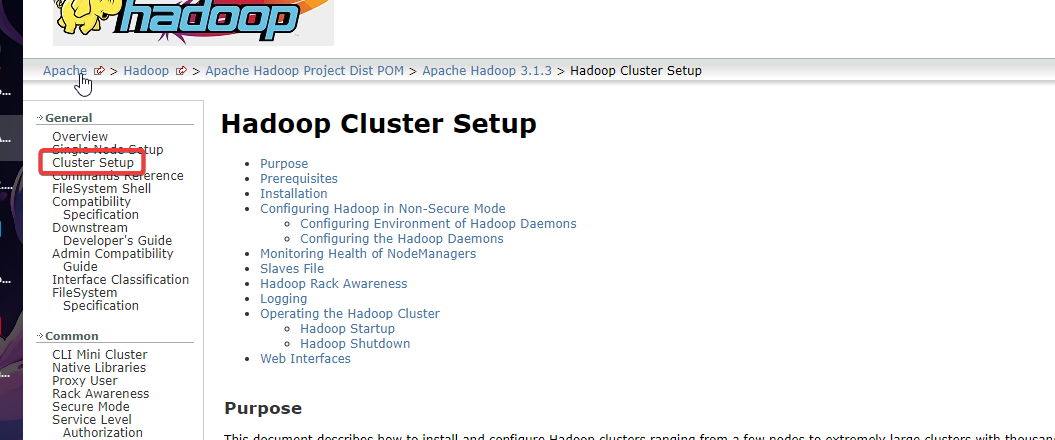
或直接查看官方配置文件:
find ./ -name "core-de*" -o -name "hdfs-de*" -o -name "mapred-de*" -o -name "yarn-de*"

(记住主要参数名即可)
2.6.1先进入配置目录
[root@master module]# cd hadoop/etc/hadoop/
[root@master hadoop]# ll
可以看到如下文件:
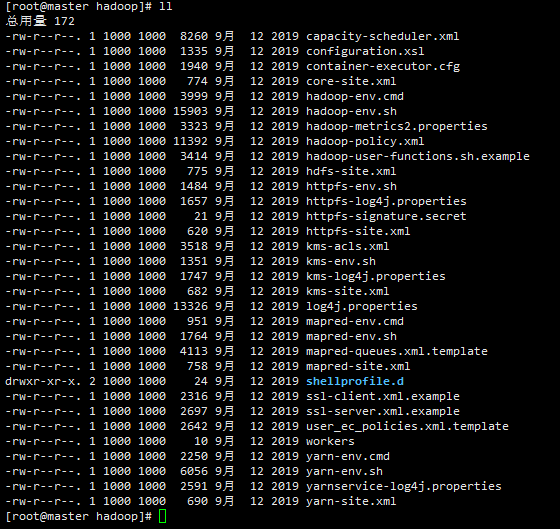
我们只用修改其中的6条
2.6.2 hadoop-env.sh配置:
[root@master hadoop]# vi hadoop-env.sh #告诉hadoop jdk在哪里

2.6.3 workers配置
(根据自己的集群来进行配置):
[root@master hadoop]# vi workers
master
slave1
slave2
2.6.4 core.site.xml配置:

[root@master hadoop]# vi core-site.xml
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopdir/tmp</value>
</property>
</configuration>
2.6.5 hdfs.site.xml:
[root@master hadoop]# vi hdfs-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoopdir/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoopdir/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!--是否开通HDFS的Web接口,3.0版本后默认端口是9870-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
2.6.6 mapred-site.xml:
[root@master hadoop]# vi mapred-site.xml
<configuration>
<!-- 指定mapreduce使用yarn资源管理器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置作业历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 配置作业历史服务器的http地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<!--确保 MapReduce 应用程序能够正确地找到 Hadoop 分发目录并加载所需的类和资源 否者会导致hive使用异常-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME={HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME={HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
2.6.7 yarn-site.xml:
[root@master hadoop]# vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- NodeManager获取数据的方式shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- yarn的web访问地址 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>master:8090</value>
</property>
<!-- 开启日志聚合功能,方便我们查看任务执行完成之后的日志记录 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
以前hadoop 2.X 版本,访问web界面,hdfs端口号是50070,现在3.X版本,端口号是9870(最好自己指定端口号)
2.6.8 配置好后分发到副节点(别忘了环境变量也要再次分发):
[root@master module]# scp /etc/profile root@slave1:/etc/profile
[root@master module]# scp /etc/profile root@slave2:/etc/profile
[root@master module]# scp -r /opt/module/hadoop root@slave1:/opt/module
[root@master module]# scp -r /opt/module/hadoop root@slave2:/opt/module
分发完后去副节点刷新环境变量
2.6.9 初始化namenode:
[root@master ~]# hdfs namenode -format
结果:

2.6.10 开启集群:
简易启动:
[root@master ~]# start-all.sh
查看结果:
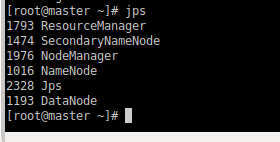
方法1:
jps
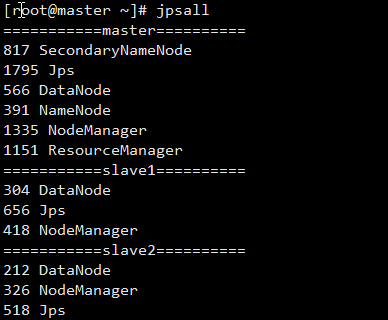
方法2:(手动添加脚本)
jpsall
结果:
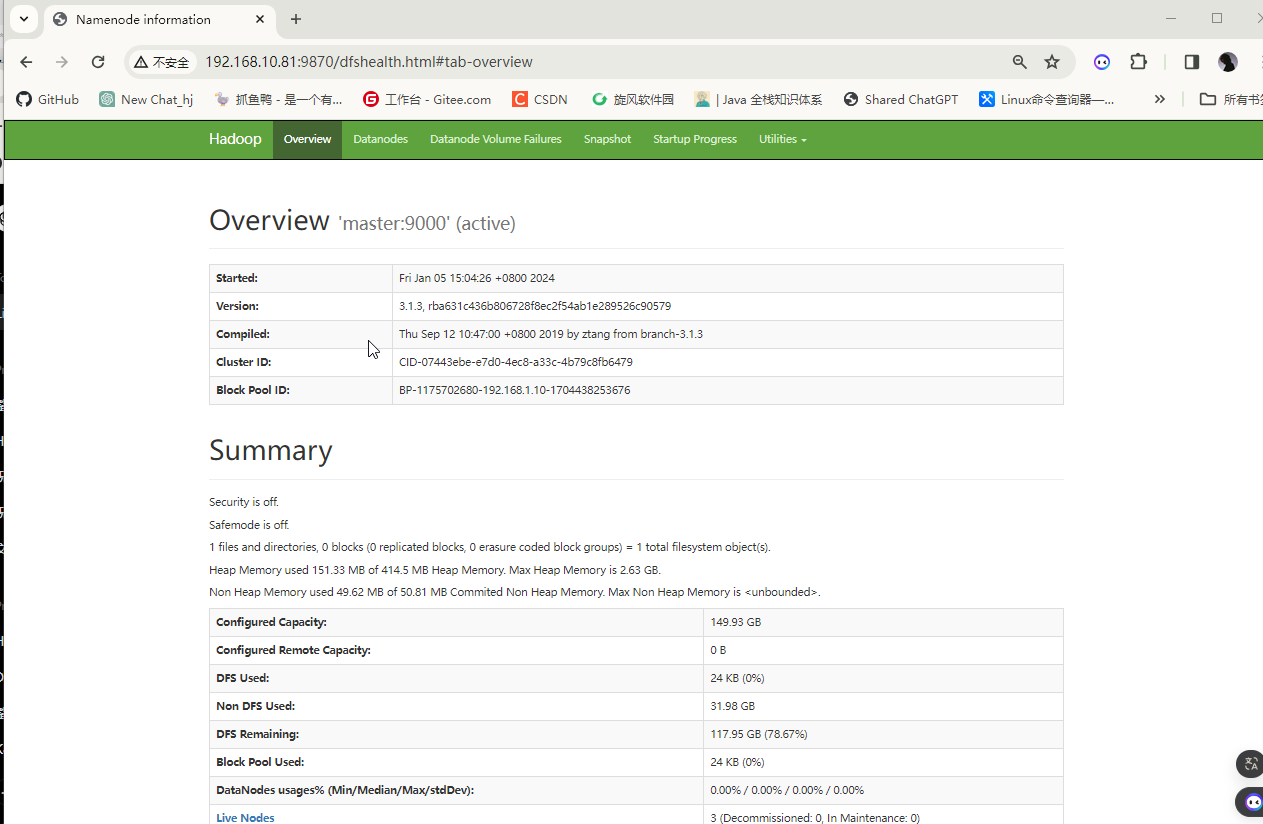
2.7 web端口访问测试
http://ip:9870
http://ip:8088
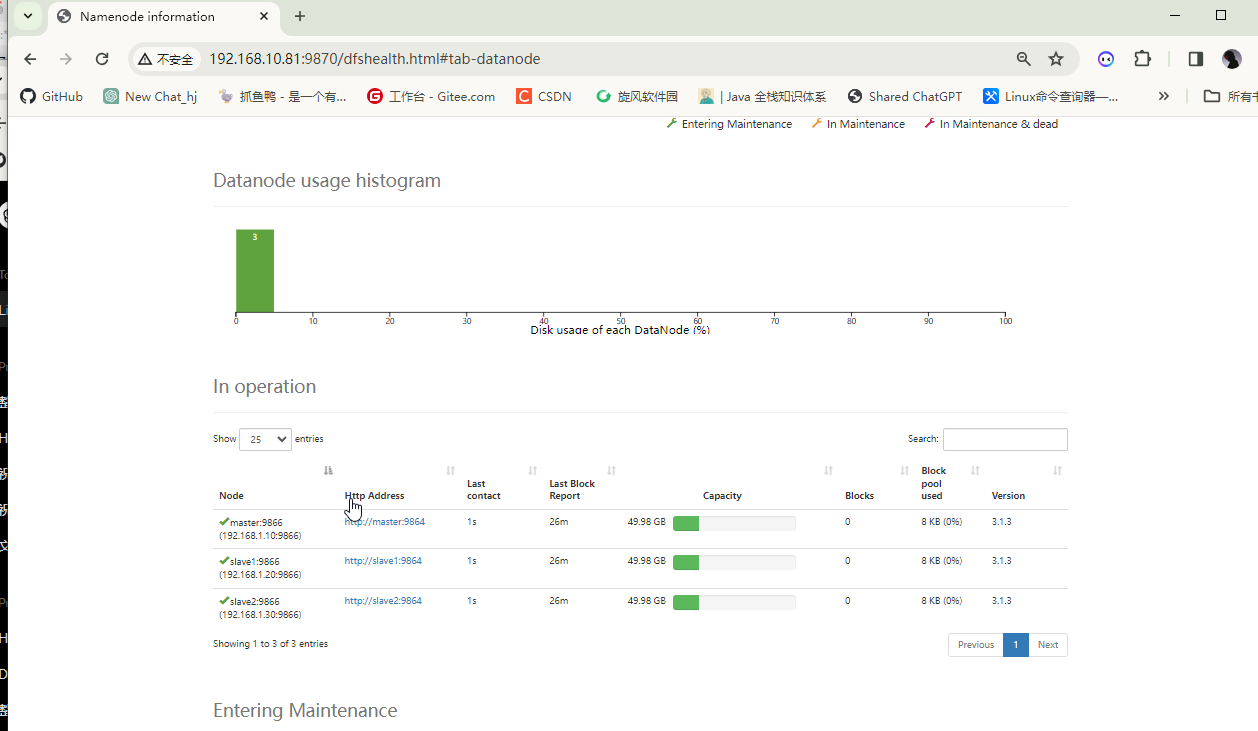
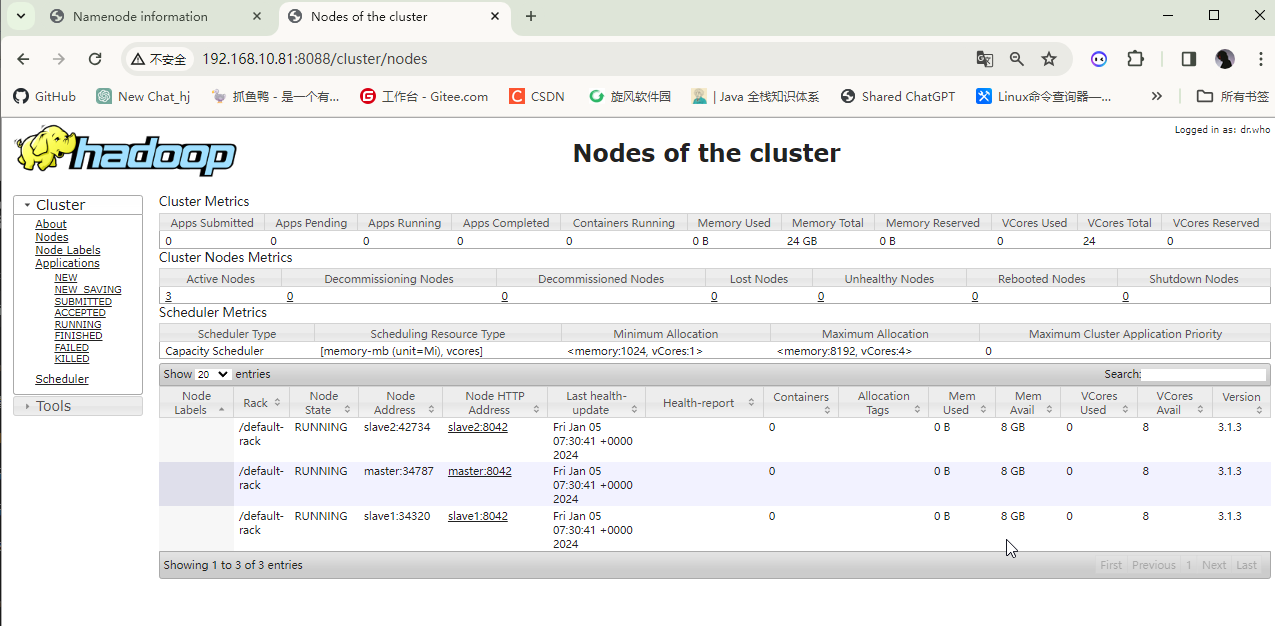
完成
3. Hadoop HA
3.1 部署zookeeper集群
3.1.1 解压所需压缩包并重命名
[root@master ~]# tar -zxvf /opt/software/zookeeper-3.4.6.tar.gz -C /opt/module/
[root@master ~]# mv /opt/module/zookeeper-3.4.6/ /opt/module/zookeeper
创建数据目录和日志目录
#数据目录
mkdir /opt/module/zookeeper/data
#日志目录
mkdir /opt/module/zookeeper/logs
3.1.2 配置环境变量
所有节点添加
添加环境变量:
#zookeeper
export ZK_HOME=/opt/module/zookeeper
export PATH=PATH:ZK_HOME/bin
刷新生效:
source /etc/profile
3.1.3 配置zoo.cfg文件
创建数据目录和日志目录
[root@master ~]# mkdir /opt/module/zookeeper/{data,logs}
[root@master ~]# cp /opt/module/zookeeper/conf/zoo_sample.cfg /opt/module/zookeeper/conf/zoo.cfg
[root@master ~]# vi /opt/module/zookeeper/conf/zoo.cfg
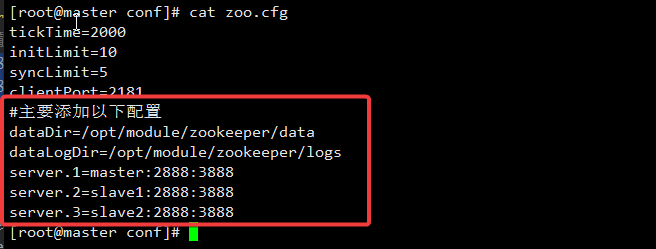
配置内容如下:
[root@master conf]# cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/module/zookeeper/data
dataLogDir=/opt/module/zookeeper/logs
clientPort=2181
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
配置详解:
[root@kafka1 opt]# grep -Ev "#|^$" /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/module/zookeeper/data
dataLogDir=/opt/module/zookeeper/logs
clientPort=2181
maxClientCnxns=4096 #(可选)
autopurge.snapRetainCount=128 # /opt/zookeeper里保存快照的最大数量(可选)
autopurge.purgeInterval=1 # 几小时清理一次(可选)
# 可以用主机名,因为设置了映射
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
配置参数解读:
server.A=B:C:D
A是一个数字,表示这个是第几号服务器。myid中的编号就是这个值。zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址。
C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
D是万一集群中的leader服务器挂了,需要一个端口来重新进行选举,选举一个新的leader,而这个端口就是用来执行选举时服务器相互通信的端口。
结果:
3.1.4 配置myid文件
[root@master zookeeper]# echo 1 > $ZK_HOME/data/myid
3.1.5 分发文件给子节点并分别修改myid文件
:warning:注意:如果子节点没有配置环境变量,也要一同分发
分发:
[root@master ~]# scp -r /opt/module/zookeeper/ root@slave1:/opt/module/
[root@master ~]# scp -r /opt/module/zookeeper/ root@slave2:/opt/module/
修改myid文件:
slave1:
[root@slave1 ~]# echo 2 > /opt/module/zookeeper/data/myid
[root@slave1 ~]# echo 2 > $ZK_HOME/data/myid
slave2:
[root@slave2 ~]# echo 3 > /opt/module/zookeeper/data/myid
[root@slave2 ~]# echo 3 > $ZK_HOME/data/myid
3.1.6 启动zk服务
所有节点启动:
/opt/module/zookeeper/bin/zkServer.sh start
查看启动状态:
/opt/module/zookeeper/bin/zkServer.sh status
master:

slave1:

slave2:

3.2 配置Hadoop HA
操作步骤和完全分布式一样,主要修改配置文件,这里从2.6开始
3.2.1 hadoop-env.sh配置
添加以下内容:
export JAVA_HOME=/opt/module/jdk1.8.0_162
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#ha新增
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
如下:
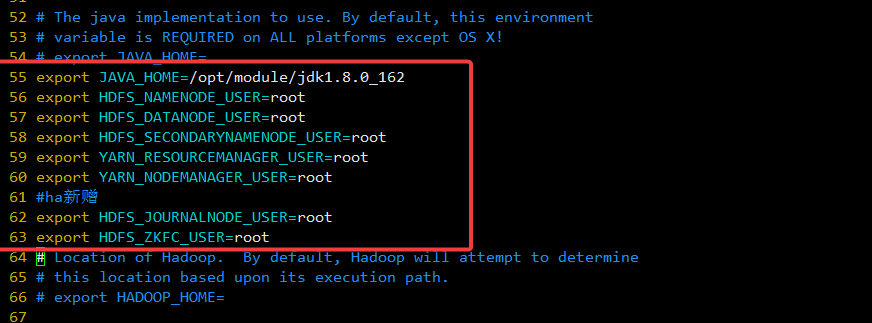
3.2.2 workers配置
添加集群信息:
[root@master hadoop]# cat workers
master
slave1
slave2
3.3.3 core-site.xml配置
[root@master hadoop]# vim core-site.xml
添加以下配置:
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopdir/tmp</value>
</property>
<!-- ha.zookeeper.quorum 指定zookeeper服务,新增配置 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>
3.3.4 hdfs-site.xml配置:star:
[root@master hadoop]# vim hdfs-site.xml
添加以下内容:
<configuration>
<!-- namenode是一个组,指定namenode的组名称,自己可以定义-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 指定namenode组的成员-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 角色1 的rpc 地址及端口号-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master:9000</value>
</property>
<!-- 角色2 的rpc 地址及端口号-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>slave1:9000</value>
</property>
<!-- Namenode 1 的地址及端口号-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master:9870</value>
</property>
<!-- Namenode 2 的地址及端口号-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>slave1:9870</value>
</property>
<!--JournalNode 的地址及端口号-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoopdir/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoopdir/dfs/data</value>
</property>
<!--JournalNode 的数据存放地址-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/hadoopdir/journal</value>
</property>
<!--Failover 类服务名-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--远程管理方式,sshfence 使用 ssh 远程管理-->
<property>
<name>dfs.ha.fencing.methods</name>
<!-- <value>sshfence</value>-->
<!--但如果只配置sshfence,如果在机器宕机后不可达,则sshfence会返回false,即fence失败,所以得要配置成-->
<value>shell(true)</value>
</property>
<!--ssh 私钥的位置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置自动故障切换,true【自动故障切换】,false【手动故障切换】-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--文件副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
3.3.5 mapred-site.xml配置
<configuration>
<!-- 指定mapreduce使用yarn资源管理器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置作业历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 配置作业历史服务器的http地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<!--确保 MapReduce 应用程序能够正确地找到 Hadoop 分发目录并加载所需的类和资源 否者会导致hive使用异常-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME={HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME={HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
3.3.6 yarn-site.xml配置:star:
<configuration>
<!-- NodeManager获取数据的方式shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--激活HA 配置-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 管理节点状态自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enable</name>
<value>true</value>
</property>
<!-- 定义数据状态保持介质 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--指定zookeeper的服务地址,为了防止单节点故障,指定三个节点-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<!--集群 ID-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
<!--定义两个 resourcemanager 角色-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--角色1 对应主机地址-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<!--角色2 对应主机地址-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<!-- 开启日志聚合功能,方便我们查看任务执行完成之后的日志记录 (可选)-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间(可选) -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
配置完成之后分发到子节点,再进行服务启动准备:warning:
3.3 服务启动准备
3.3.1 启动journalnode服务
所有节点启动journalnode
hadoop-daemon.sh start journalnode
3.3.2 初始化namenode
master(
nn1)节点初始化namenode
hdfs namenode -format
结果如下:
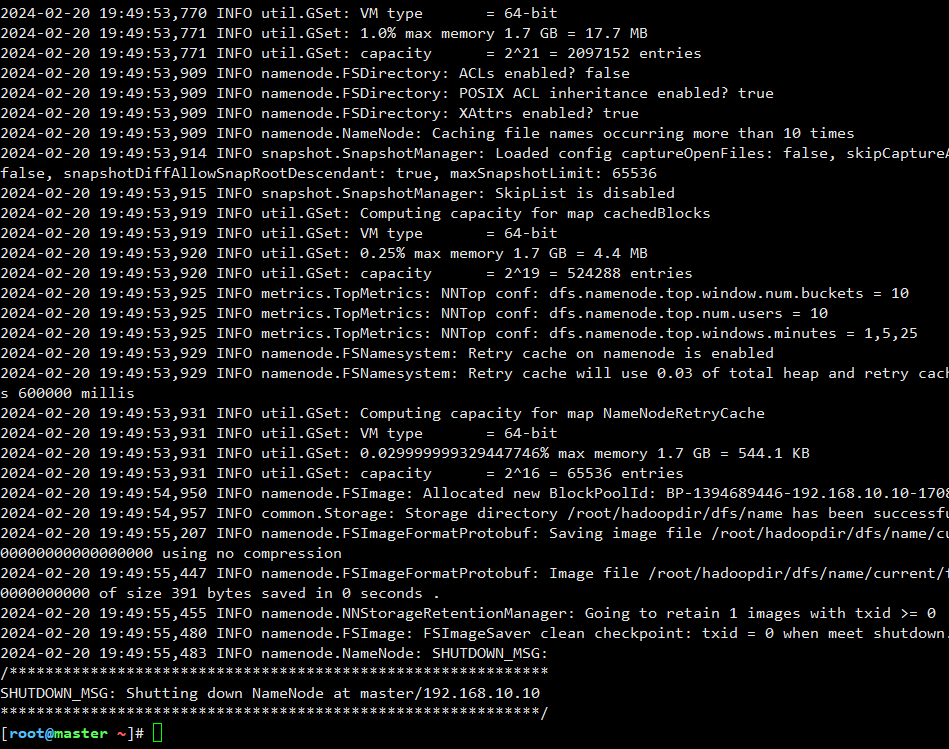
同步元数据到
nn2(slave1)
:one: 方式1: 直接从主节点(nn1)发送到主节点(nn2)
scp -r hadoopdir/dfs/ root@slave1:/root/hadoopdir

:two: 方式2:在主节点(nn2)使用指令同步
首先需要在主几点(nn1)启动namenode服务,否则在主节点(nn2)节点中同步元数据会失败,
提示找不到master的namenode服务,如下图:

关键错误是“Connection refused”,这表明备用NameNode无法连接到活动NameNode(192.168.10.11:9000)。
正确步骤如下:
1.在master(nn1)启动namenode服务:
[root@master ~]# hdfs --daemon start namenode
2.在slave1(nn2)使用指令同步元数据
[root@slave1 ~]# hdfs namenode -bootstrapStandby
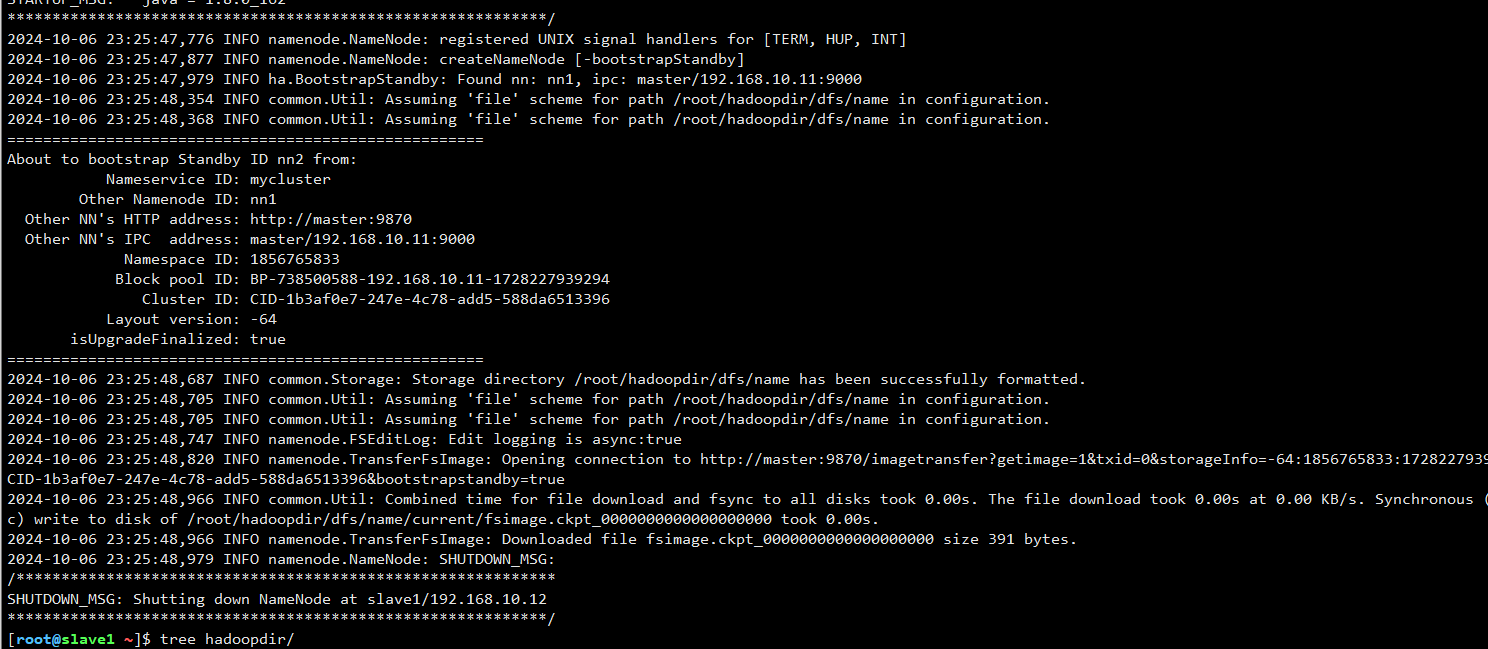
同步需要进一步确定是否成功,可以直接查看/root/hadoopdir数据目录下是否成功同步过来,如下图:
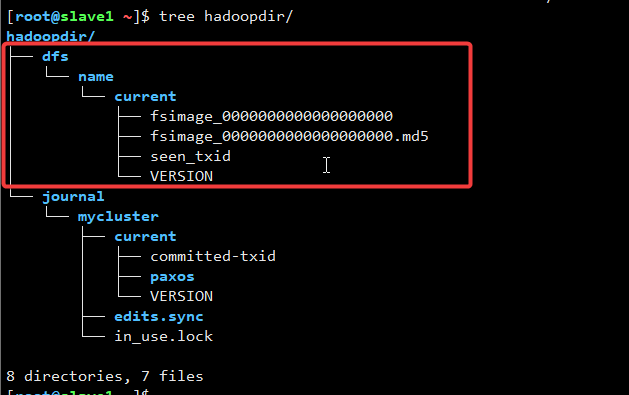
(方式2和方式1一样,所以我觉得直接使用scp更高效点ovO…)
3.3.3 master节点初始化zk
hdfs zkfc -formatZK
结果如下:
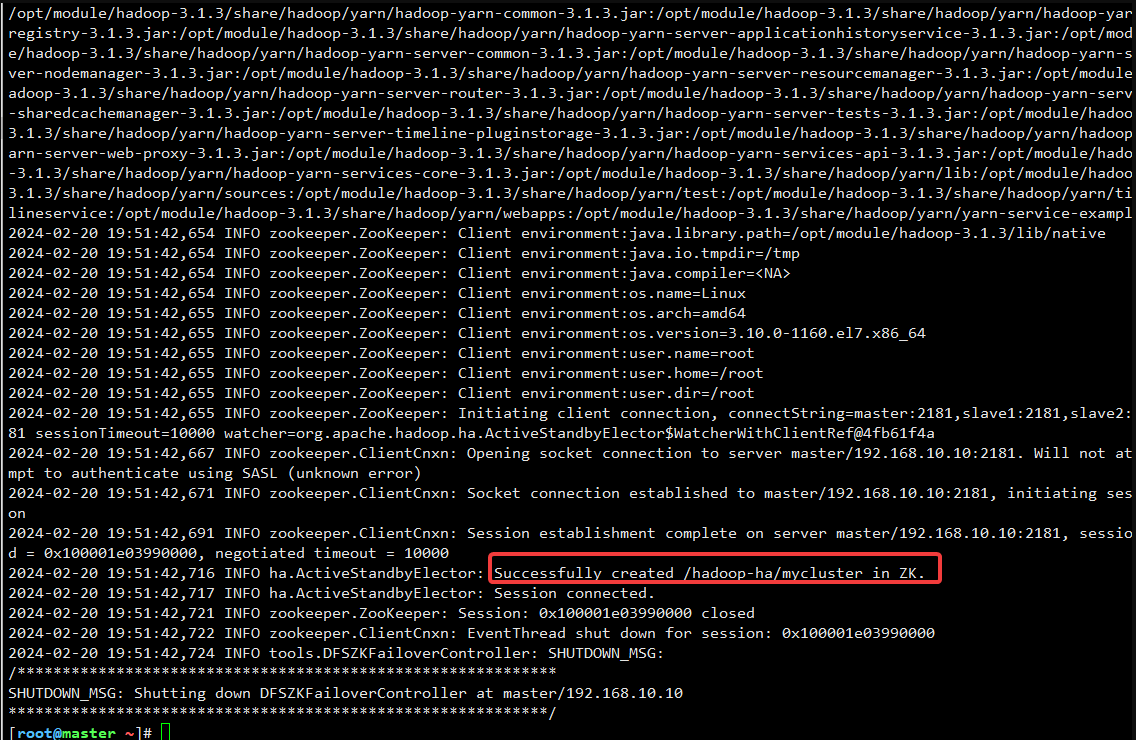
3.3.4 启动集群
在主节点(master)执行:
start-all.sh
所有节点启动(已启动则忽略):
hadoop-daemon.sh start journalnode
启动后的进程如下:
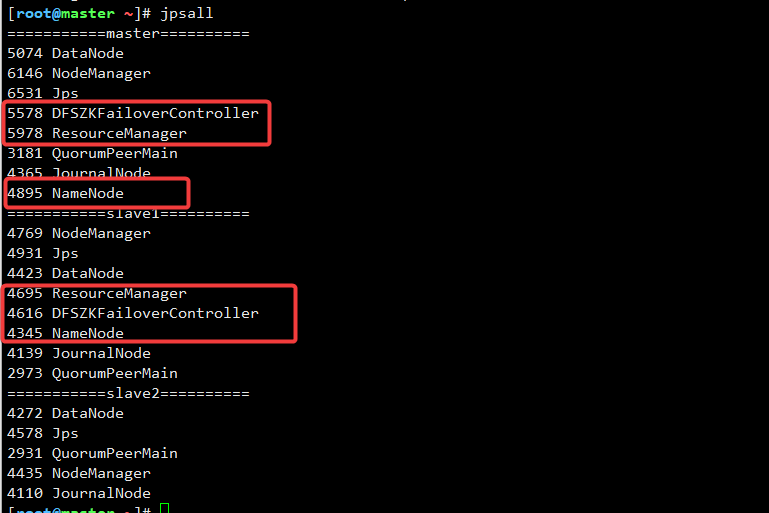
3.4 使用命令分别查看服务nn2与rm2进程状态
[root@master ~]# hdfs haadmin -getServiceState nn2
active

[root@master ~]# yarn rmadmin -getServiceState rm2
active

全部服务状态:
[root@master ~]# yarn rmadmin -getServiceState rm1
standby
[root@master ~]# yarn rmadmin -getServiceState rm2
active
[root@master ~]# hdfs haadmin -getServiceState nn1
standby
[root@master ~]# hdfs haadmin -getServiceState nn2
active
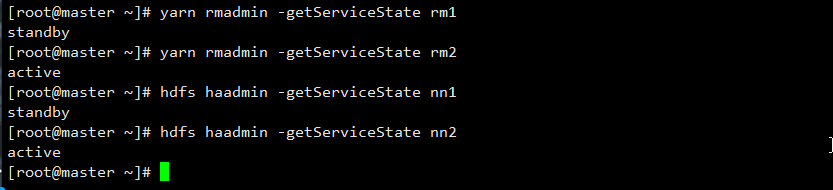
3.5 测试HA
单服务启动的方式:
hdfs --daemon start namenode
进入192.168.10.10:9870 / master:9870
主节点
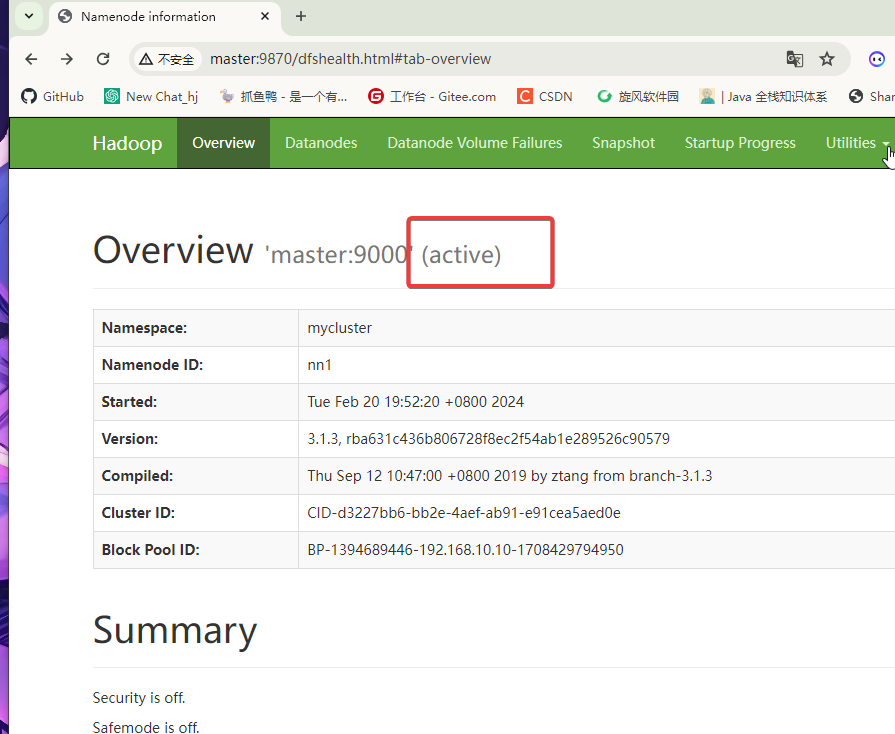
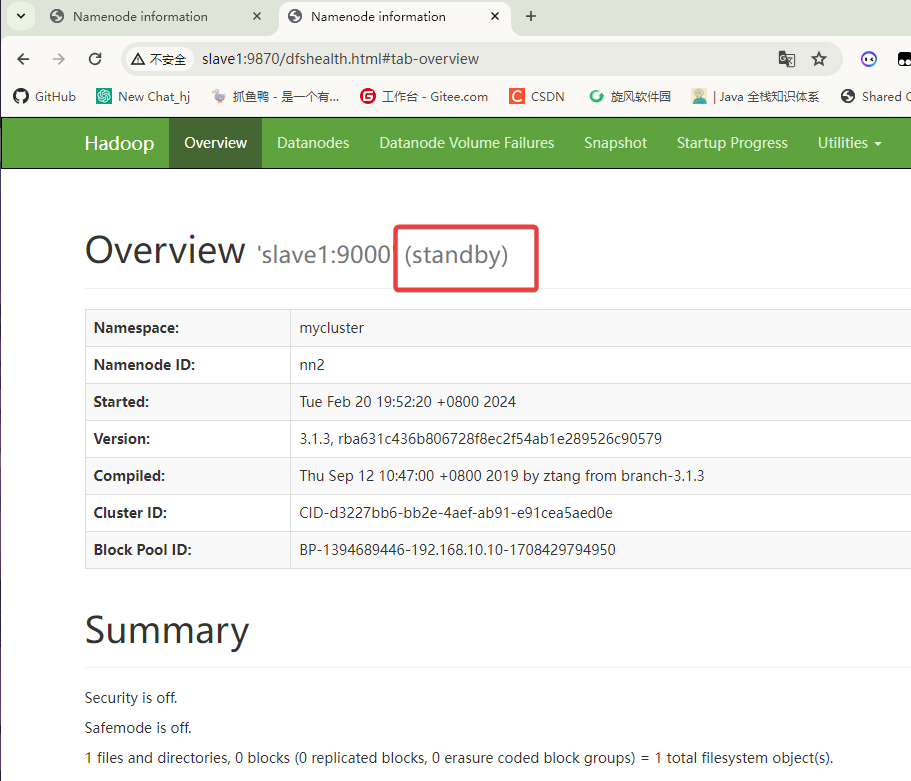
进入192.168.10.20:9870 / slave1:9870
备用节点
kill 掉master的namenode服务刷新slave1的web端查看
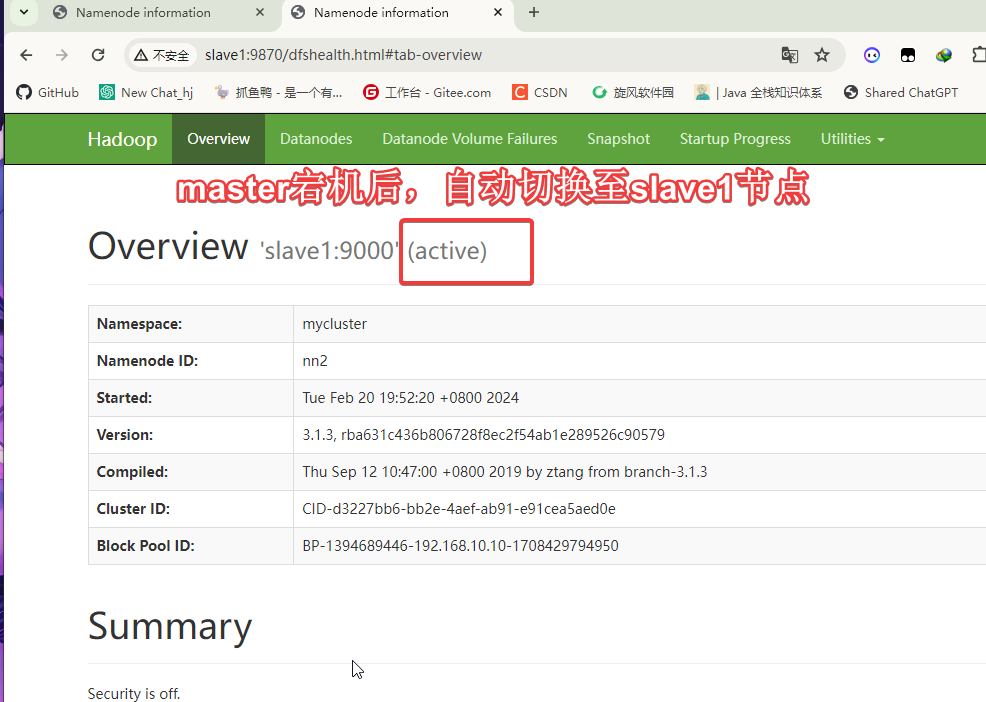
master的web端口:
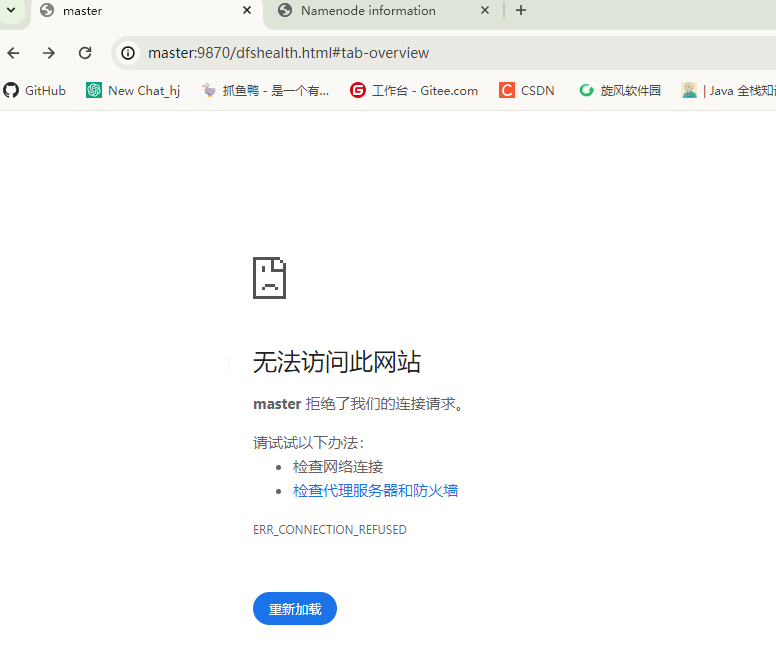
发现此时的master节点的namenode已经无法访问,这里手动启动namenode服务:
[root@master ~]# hdfs --daemon start namenode
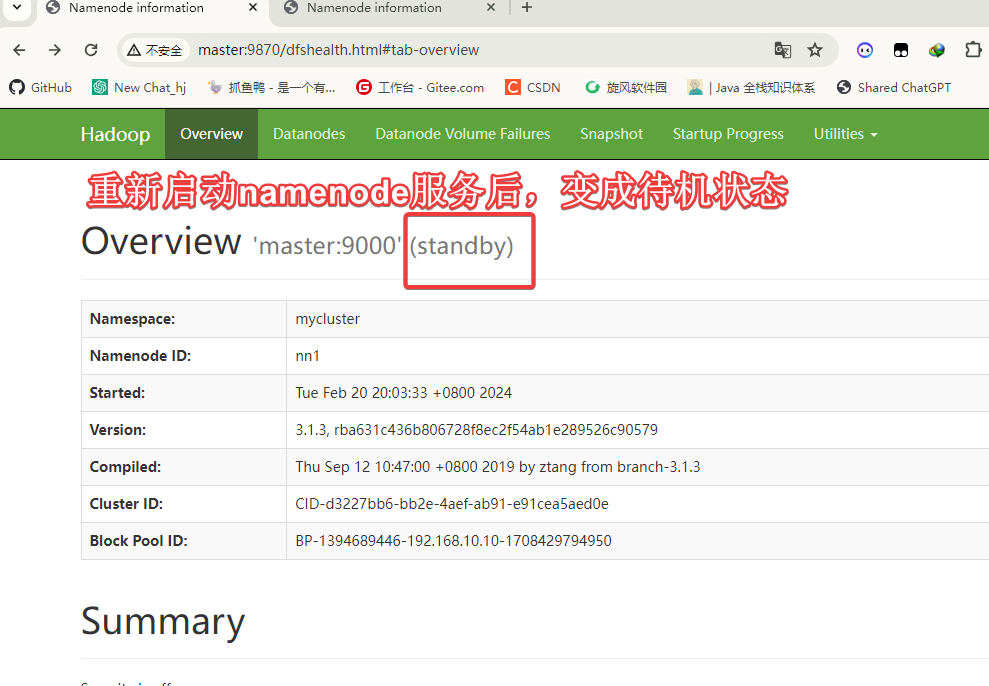
Hadoop HA部署完成
4. HDFS 操作指令
常用指令:
| 参数 | 作用 |
|---|---|
| hdfs dfs -cat | 用于查看分布式文件系统中指定文件里面的内容 |
| hdfs dfs -chmod -R | 对分布式文件系统中的文件进行授权 |
| hdfs dfs -copyFromLocal -f -l -p | 把本地的文件复制到 HDFS 路径中 |
| hdfs dfs -copyToLocal -p -ignoreCrc | 把分布式文件系统中的文件复制到本地路径中 |
| hdfs dfs -put (-f -p -l) | 用于来将本地的文件上传到HDFS分布式文件系统中 |
| Hdfs dfs -find | 作用是用于查询分布式文件系统中的文件 |
| hdfs dfs -help | 用来显示分布式文件系统的所有操作,获取帮助。相当于我们平时所看到的说明书 |
| hdfs dfs -mv | 将分布式文件系统中的文件进行移动 |
| hdfs dfs -moveFromLocal | 把本地的文件移动到分布式文件系统中(从本地剪切粘贴到HDFS) |
| hdfs dfs -moveToLocal | 把分布式文件系统中的文件移动到本地中(从HDFS将文件剪切粘贴到本地) |
| hdfs dfs -mkdir -p | 用来创建HDFS分布式文件系统中的文件 |
| hdfs dfs -rm -f -r | 将分布式文件系统中的文件进行删除 |
| hdfs dfs -rmdir | 用来进行递归删除文件/文件夹,文件夹中有文件也能删除 |
全部指令:
1、hdfs dfs -cat :用于查看分布式文件系统中指定文件里面的内容
2、hdfs dfs -checksum:用来查看指定文件的MD5值
3、hdfs dfs -chmod -R:对分布式文件系统中的文件进行授权
4、Hdfs dfs -copyFromLocal -f -l -p:把本地的文件复制到 HDFS 路径中
5、Hdfs dfs -copyToLocal -p -ignoreCrc :把分布式文件系统中的文件复制到本地路径中
6、Hdfs dfs -count -q -h:用来进行统计计数操作
7、dfs dfs -count -q -h:用来进行统计计数操作
8、Hdfs dfs -cp -f -p:该命令的作用相当于我们windwos下的复制命令,作用是从 HDFS 的一个路径复制(拷贝)到 HDFS 的另一个路径
9、Hdfs dfs -createSnapshot :用来创建分布式文件系统的快照
10、Hdfs dfs -deleteSnapshot:作用是用于删除分布式文件系统的快照
11、Hdfs dfs -df -h:用于查看分布式文件系统硬盘的使用情况
12、Hdfs dfs -du -s -h:用来查看分布式文件系统中指定文件的大小
13、Hdfs dfs -expunge:用来对分布式文件系统中垃圾箱进行清空操作
14、Hdfs dfs -find:作用是用于查询分布式文件系统中的文件
15、Hdfs dfs -get -p -crc -ignoreCrc:作用是将分布式文件系统中的文件传输到本地机器上,相当于下载
16、hdfs dfs -getfacl -R:获取对象或目录的 ACL(访问控制列表)
17、hdfs dfs -getfatter -R:获取对象或目录的扩展属性
18、hdfs dfs -getmerge -nl:获取对象属性
19、hdfs dfs -help:用来显示分布式文件系统的所有操作,获取帮助。相当于我们平时所看到的说明书
20、hdfs dfs -ls -d -h -R :该命令的作用是列出分布式文件系统中指定路径下的文件列表
21、hdfs dfs -mkdir -p:用来创建HDFS分布式文件系统中的文件
22、hdfs dfs -moveFromLocal:把本地的文件移动到分布式文件系统中(从本地剪切粘贴到HDFS)
23、hdfs dfs -moveToLocal:把分布式文件系统中的文件移动到本地中(从HDFS将文件剪切粘贴到本地)
24、hdfs dfs -mv:将分布式文件系统中的文件进行移动
25、hdfs dfs -put (-f -p -l):用于来将本地的文件上传到HDFS分布式文件系统中
26、hdfs dfs -renameSnapshot:用于对分布式文件系统中的快照进行更名
27、hdfs dfs -rm -f -r:将分布式文件系统中的文件进行删除
28、hdfs dfs -rmdir :用来进行递归删除文件/文件夹,文件夹中有文件也能删除
29、hdfs dfs -setfacl -R:设置对象或目录的 ACL(访问控制列表)
30、hdfs dfs -setfattr -n:设置对象或目录的扩展属性
31、hdfs dfs -setrep -R:用来设置 HDFS 中文件的副本数量
32、hdfs dfs -stat:根据格式显示指定对象的信息
33、hdfs dfs -tail -f:作用是显示指定文件的末尾
34、hdfs dfs -test:用来判断指定文件的类型
35、hdfs dfs -text:作用是以字符形式打印一个文件的内容