HBase分布式集群部署与Scala API开发实战指南
1.初识HBase
HBase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。HBase 底层存储基于 HDFS 实现,集群的管理基于 ZooKeeper 实现。HBase 良好的分布式架构设计为海量数据的快速存储、随机访问提供了可能,基于数据副本机制和分区机制可以轻松实现在线扩容、缩容和数据容灾,是大数据领域中 Key-Value 数据结构存储最常用的数据库方案。
1.1 HBase特点
:one:易扩展
Hbase 的扩展性主要体现在两个方面,一个是基于运算能力(RegionServer) 的扩展,通过增加 RegionSever 节点的数量,提升 Hbase 上层的处理能力;另一个是基于存储能力的扩展(HDFS),通过增加 DataNode 节点数量对存储层的进行扩容,提升 HBase 的数据存储能力。
:two:海量存储
HBase 作为一个开源的分布式 Key-Value 数据库,其主要作用是面向 PB 级别数据的实时入库和快速随机访问。这主要源于上述易扩展的特点,使得 HBase 通过扩展来存储海量的数据。
:three: 列式存储
Hbase 是根据列族来存储数据的。列族下面可以有非常多的列。列式存储的最大好处就是,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。
:four:高可靠性
WAL 机制保证了数据写入时不会因集群异常而导致写入数据丢失,Replication 机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且 Hbase 底层使用 HDFS,HDFS 本身也有备份。
:five:稀疏性
在 HBase 的列族中,可以指定任意多的列,为空的列不占用存储空间,表可以设计得非常稀疏。
1.2 模块组成
HBase 可以将数据存储在本地文件系统,也可以存储在 HDFS 文件系统。在生产环境中,HBase 一般运行在 HDFS 上,以 HDFS 作为基础的存储设施。HBase 通过 HBase Client 提供的 Java API 来访问 HBase 数据库,以完成数据的写入和读取。HBase 集群主由HMaster、Region Server 和 ZooKeeper组成。
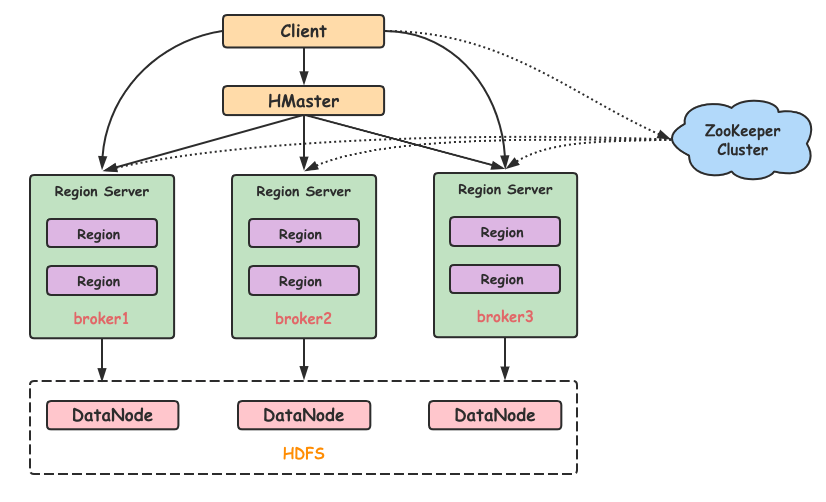
:one: HMaster
- 负责管理 RegionServer,实现其负载均衡;
- 管理和分配 Region,比如在 Region split时分配新的 Region,在 RegionServer 退出时迁移其内的 Region 到其他 RegionServer上;
- 管理namespace和table的元数据(实际存储在HDFS上);
- 权限控制(ACL)。
:two: RegionServer
- 存放和管理本地 Region;
- 读写HDFS,管理Table中的数据;
- Client 从 HMaster 中获取元数据,找到 RowKey 所在的 RegionServer 进行读写数据。
:three: ZooKeeper
- 存放整个 HBase集群的元数据以及集群的状态信息;
- 实现HMaster主从节点的failover。
2. HBase 数据模型
HBase 是一个面向列式存储的分布式数据库。HBase 的数据模型与 BigTable 十分相似。在 HBase 表中,一条数据拥有一个全局唯一的键(RowKey)和任意数量的列(Column),一列或多列组成一个列族(Column Family),同一个列族中列的数据在物理上都存储在同一个 HFile 中,这样基于列存储的数据结构有利于数据缓存和查询。 HBase 中的表是疏松地存储的,因此用户可以动态地为数据定义各种不同的列。HBase中的数据按主键排序,同时,HBase 会将表按主键划分为多个 Region 存储在不同 Region Server 上,以完成数据的分布式存储和读取。
HBase 根据列成来存储数据,一个列族对应物理存储上的一个 HFile,列族包含多列列族在创建表的时候被指定。
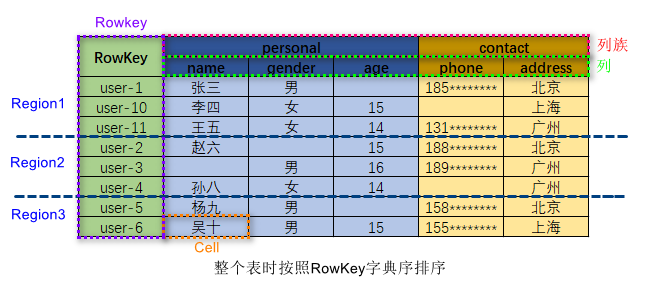
2.1 Column Family
Column Family 即列族,HBase 基于列划分数据的物理存储,一个列族可以包含包意多列。
一般同一类的列会放在一个列族中,每个列族都有一组存储属性:
- 是否应该缓存在内存中;- 数据如何被压缩或行键如何编码等。
HBase 在创建表的时候就必须指定列族。HBase的列族不是越多越好,官方荐一个表的列族数量最好小于或者等于3,过多的列族不利于 HBase 数据的管理和索引。
2.2 RowKey
RowKey的概念与关系型数据库中的主键相似,HBase 使用 RowKey 来唯一标识某行的数据。
访问 HBase 数据的方式有三种:
- 基于 RowKey的单行查询;- 基于RowKey的范围查询;- 全表扫描查询。
2.3 Region
HBase 将表中的数据基于 RowKey 的不同范围划分到不同 Region 上,每个Region都负责一定范围的数据存储和访问。
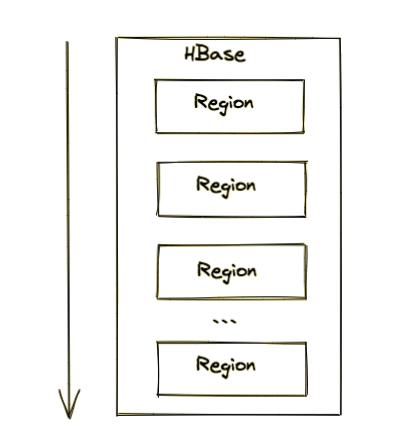
每个表一开始只有一个 Region,随着数据不断插入表,Region 不断增大,当增大到一个阀值的时候,Region 就会等分成两个新的 Region。当table中的行不断增多,就会有越来越多的 Region。
另外,Region 是 Hbase 中分布式存储和负载均衡的最小单元,不同的 Region 可以分布在不同的 HRegion Server上。但一个Hregion是不会拆分到多个server上的。
这样即使有一个包括上百亿条数据的表,由于数据被划分到不同的 Region上,每个 Region 都可以独立地进行写入和查询,HBase 写查询时候可以于多 Region 分布式并发操作,因此访问速度也不会有太大的降低。
2.4 TimeStamp
TimeStamp 是实现 HBase 多版本的关键。在HBase 中,使用不同 TimeStamp 来标识相同RowKey对应的不同版本的数据。相同 RowKey的数据按照 TimeStamp 倒序排列。默认查询的是最新的版本,当然用户也可以指定 TimeStamp 的值来读取指定版本的数据。
3. 列式存储会被广泛用在OLAP中
OLTP(on-line transaction processing)为联机事务处理。
OLAP(On-Line Analytical Processing)为联机分析处理。两者简单的区别为OLTP是做事务处理,OLAP是做分析处理。
站在数据库的操作层面来看,OLTP主要是对数据的增删改,侧重实时性,OLAP是对数据的查询,侧重大数据量查询。
不知是否有小伙伴们疑问,为什么列式存储会广泛地应用在 OLAP 领域,和行式存储相比,它的优势在哪里?今天我们一起来对比下这两种存储方式的差别。
其实,列式存储并不是一项新技术,最早可以追溯到 1983 年的论文 Cantor。然而,受限于早期的硬件条件和应用场景,传统的事务型数据库(OLTP)如 Oracle、MySQL 等关系型数据库都是以行的方式来存储数据的。
直到近几年分析型数据库(OLAP)的兴起,列式存储这一概念又变得流行,如 HBase、Cassandra 等大数据相关的数据库都是以列的方式来存储数据的。
3.1 行式存储的原理与特点
对于 OLAP 场景,大多都是对一整行记录进行增删改查操作的,那么行式存储采用以行的行式在磁盘上存储数据就是一个不错的选择。
当查询基于需求字段查询和返回结果时,由于这些字段都埋藏在各行数据中,就必须读取每一条完整的行记录,大量磁盘转动寻址的操作使得读取效率大大降低。
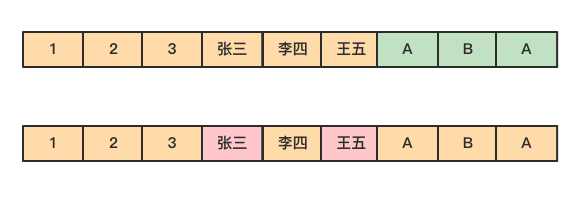
举个例子,下图为员工信息emp表。
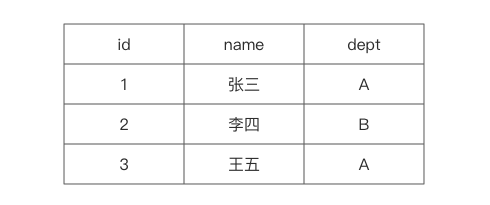
数据在磁盘上是以行的形式存储在磁盘上,同一行的数据紧挨着存放在一起。
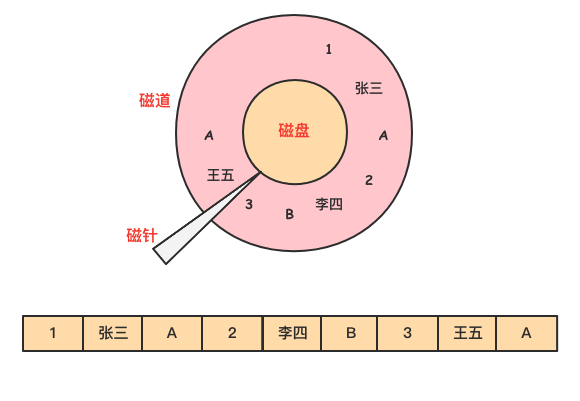
对于 emp 表,要查询部门 dept 为 A 的所有员工的名字。
select name from emp where dept = A
由于 dept 的值是离散地存储在磁盘中,在查询过程中,需要磁盘转动多次,才能完成数据的定位和返回结果。
3.2 列式存储的原理与特点
对于 OLAP 场景,一个典型的查询需要遍历整个表,进行分组、排序、聚合等操作,这样一来行式存储中把一整行记录存放在一起的优势就不复存在了。而且,分析型 SQL 常常不会用到所有的列,而仅仅对其中某些需要的的列做运算,那一行中无关的列也不得不参与扫描。
然而在列式存储中,由于同一列的数据被紧挨着存放在了一起,如下图所示。
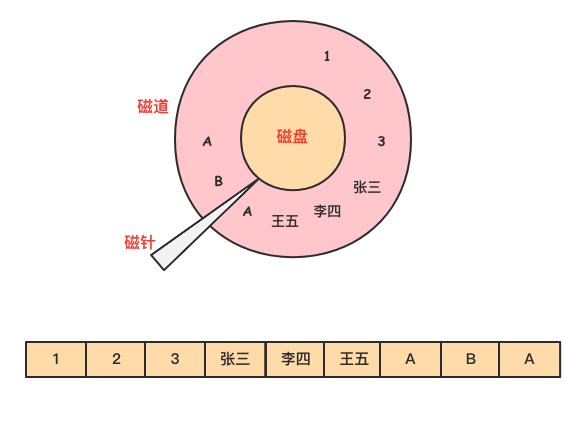
那么基于需求字段查询和返回结果时,就不许对每一行数据进行扫描,按照列找到需要的数据,磁盘的转动次数少,性能也会提高。
还是上面例子中的查询,由于在列式存储中 dept 的值是按照顺序存储在磁盘上的,因此磁盘只需要顺序查询和返回结果即可。
列式存储不仅具有按需查询来提高效率的优势,由于同一列的数据属于同一种类型,如数值类型,字符串类型等,相似度很高,还可以选择使用合适的编码压缩可减少数据的存储空间,进而减少IO提高读取性能。
总的来说,行式存储和列式存储没有说谁比谁更优越,只能说谁更适合哪种应用场景。
4. HBase 的架构组成
HBase 作为 NoSQL 数据库的代表,属于三驾马车之一 BigTable 的对应实现,HBase 的出现很好地弥补了大数据快速查询能力的空缺。
HBase 的核心架构由五部分组成,分别是 HBase Client、HMaster、Region Server、ZooKeeper 以及 HDFS。它的架构组成如下图所示。
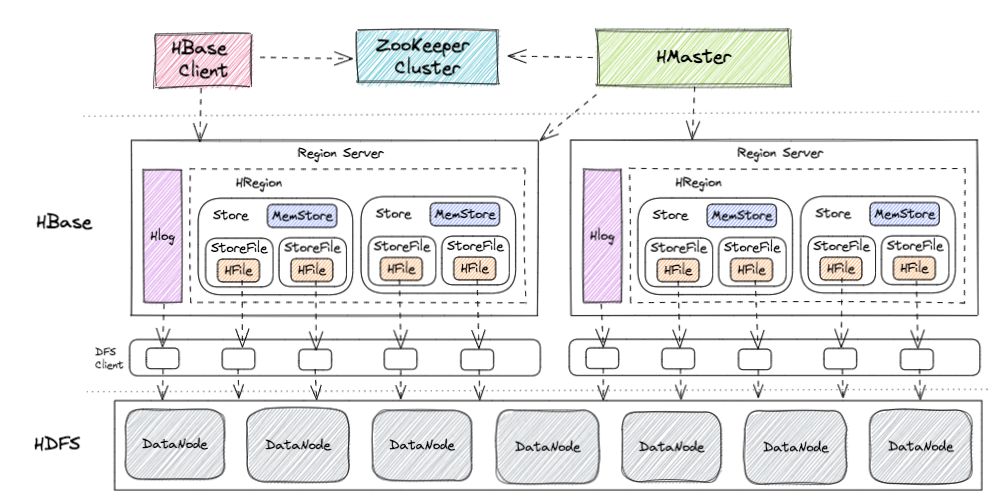
:one: HBase Client
HBase Client 为用户提供了访问 HBase 的接口,可以通过元数据表来定位到目标数据的 RegionServer,另外 HBase Client 还维护了对应的 cache 来加速 Hbase 的访问,比如缓存元数据的信息。
:two: HMaster
HMaster 是 HBase 集群的主节点,负责整个集群的管理工作,主要工作职责如下:
- 分配Region:负责启动的时候分配Region到具体的 RegionServer;
- 负载均衡:一方面负责将用户的数据均衡地分布在各个 Region Server 上,防止Region Server数据倾斜过载。另一方面负责将用户的请求均衡地分布在各个 Region Server 上,防止Region Server 请求过热;
- 维护数据:发现失效的 Region,并将失效的 Region 分配到正常的 RegionServer 上,并且在Region Sever 失效的时候,协调对应的HLog进行任务的拆分。
:three: Region Server
Region Server 直接对接用户的读写请求,是真正的干活的节点,主要工作职责如下:
- 管理 HMaster 为其分配的 Region;
- 负责与底层的 HDFS 交互,存储数据到 HDFS;
- 负责 Region 变大以后的拆分以及 StoreFile 的合并工作。与 HMaster 的协同:当某个 RegionServer 宕机之后,ZK 会通知 Master 进行失效备援。下线的 RegionServer 所负责的 Region 暂时停止对外提供服务,Master 会将该 RegionServer 所负责的 Region 转移到其他 RegionServer 上,并且会对所下线的 RegionServer 上存在 MemStore 中还未持久化到磁盘中的数据由 WAL 重播进行恢复。
Region Serve数据存储的基本结构,如下图所示。一个 Region Server 是包含多个 Region 的,这里仅展示一个:

- Region:每一个 Region 都有起始 RowKey 和结束 RowKey,代表了存储的Row的范围,保存着表中某段连续的数据。一开始每个表都只有一个 Region,随着数据量不断增加,当 Region 大小达到一个阀值时,Region 就会被 Regio Server 水平切分成两个新的 Region。当 Region 很多时,HMaster 会将 Region 保存到其他 Region Server 上。
-
Store:一个 Region 由多个 Store 组成,每个 Store 都对应一个 Column Family, Store 包含 MemStore 和 StoreFile。
- MemStore:作为HBase的内存数据存储,数据的写操作会先写到 MemStore 中,当MemStore 中的数据增长到一个阈值(默认64M)后,Region Server 会启动 flasheatch 进程将 MemStore 中的数据写人 StoreFile 持久化存储,每次写入后都形成一个单独的 StoreFile。当客户端检索数据时,先在 MemStore中查找,如果MemStore 中不存在,则会在 StoreFile 中继续查找。
- StoreFile:MemStore 内存中的数据写到文件后就是StoreFile,StoreFile底层是以 HFile 的格式保存。HBase以Store的大小来判断是否需要切分Region。
当一个Region 中所有 StoreFile 的大小和数量都增长到超过一个阈值时,HMaster 会把当前Region分割为两个,并分配到其他 Region Server 上,实现负载均衡。
- HFile:HFile 和 StoreFile 是同一个文件,只不过站在 HDFS 的角度称这个文件为HFile,站在HBase的角度就称这个文件为StoreFile。
- HLog:负责记录着数据的操作日志,当HBase出现故障时可以进行日志重放、故障恢复。例如,磁盘掉电导致 MemStore中的数据没有持久化存储到 StoreFile,这时就可以通过HLog日志重放来恢复数据。
:four: ZooKeeper
HBase 通过 ZooKeeper 来完成选举 HMaster、监控 Region Server、维护元数据集群配置等工作,主要工作职责如下:
- 选举HMaster:通ooKeeper来保证集中有1HMaster在运行,如果 HMaster 异常,则会通过选举机制产生新的 HMaster 来提供服务;
- 监控Region Server: 通过 ZooKeeper 来监控 Region Server 的状态,当Region Server 有异常的时候,通过回调的形式通知 HMaster 有关Region Server 上下线的信息;
- 维护元数据和集群配置:通过ooKeeper储B信息并对外提供访问接口。
:five: HDFS
HDFS 为 HBase 提供底层数据存储服务,同时为 HBase提供高可用的支持, HBase 将 HLog 存储在 HDFS 上,当服务器发生异常宕机时,可以重放 HLog 来恢复数据。
5. HBase 的写入流程
写入流程如下图所示:
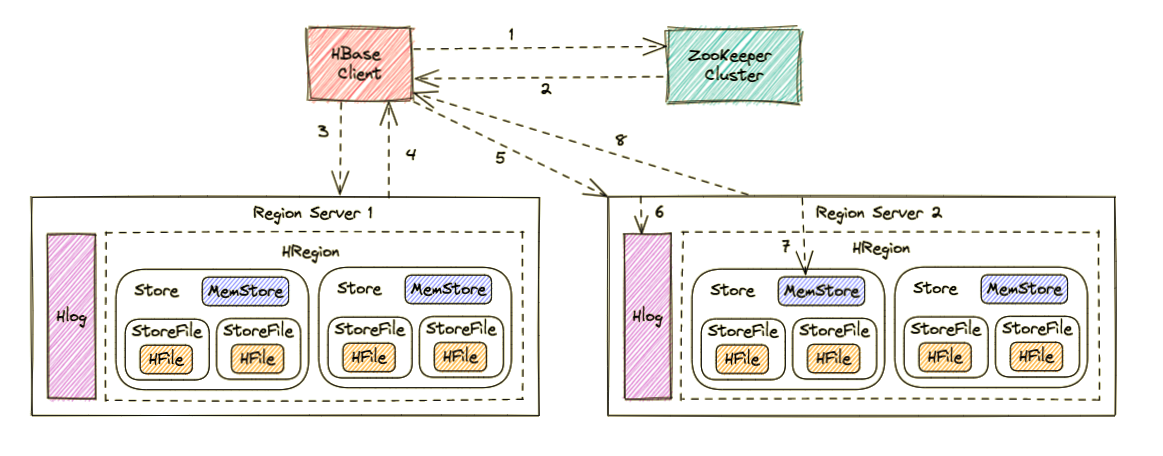
Region Server 寻址
- HBase Client 访问 ZooKeeper;
-
获取写入 Region 所在的位置,即获取 hbase:meta 表位于哪个 Region Server;
-
访问对应的 Region Server;
-
获取 hbase:meta 表,并查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 Region 信息以及 meta 表的位置信息缓存在客户端的meta cache,方便下次访问;
写 Hlog
- HBase Client 向 Region Server 发送写 Hlog 请求;
- Region Server 会通过顺序写入磁盘的方式,将 Hlog 存储在 HDFS 上;
写 MemStore 并返回结果
- HBase Client 向 Region Server 发送写 MemStore 请求;
- 只有当写 Hlog 和写 MemStore 的请求都成功完成之后,并将反馈给 HBase Client,这时对于整个 HBase Client 写入流程已经完成。
MemStore 刷盘
HBase 会根据 MemStore 配置的刷盘策略定时将数据刷新到 StoreFile 中,完成数据持久化存储。
6. HBase 的读流程
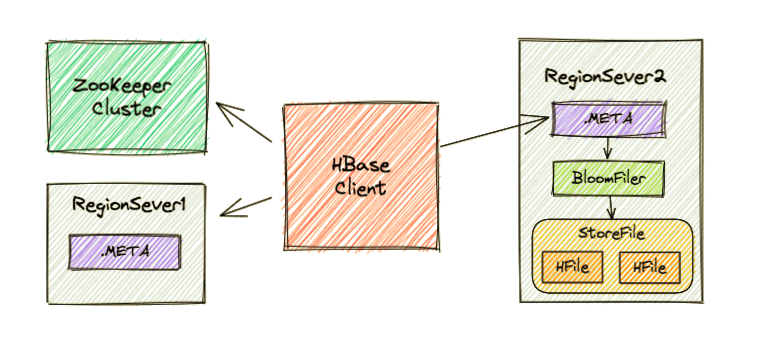
Region Server 寻址
HBase Client 请求 ZooKeeper 获取元数据表所在的 Region Server的地址。
Region 寻址
HBase Client 请求 RegionServer 获取需要访问的元数据,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以 及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
数据读取
HBase Client 请求数据所在的 Region Server,获取所需要的数据。 Region 首先在 MemStore 中查找,若命中则返回;如果在MemStore 中找不到,则通过 BloomFilter 判断数据是否存在;如果存在,则在:StoreFile 中扫描并将结果返回客户端。
7. HBase 的数据删除
HBase 的数据删除操作并不会立即将数据从磁盘上删除,因为 HBase 的数据通常被保存在 HDFS 中,而 HDFS 只允许新增或者追加数据文件,所以删除操作主要对要被删除的数据进行标记。
当执行删除操作时,HBase 新插入一条相同的 Key-Value 数据,但是 keyType=Delete,这便意味着数据被删除了,直到发生 Major_compaction 操作,数据才会真正地被从磁盘上删除。
HBase这种基于标记删除的方式是按顺序写磁盘的的,因此很容易实现海量数据的快速删除,有效避免了在海量数据中查找数据、执行删除及重建索引等复杂的流程。
8. Hbase完全分布式部署
实验环境:
| 容器系统 | 容器主机名 | 容器ip | 容器用户名 |
|---|---|---|---|
| centos7 | master | 192.168.1.10 | root |
| centos7 | slave1 | 192.168.1.20 | root |
| centos7 | slave2 | 192.168.1.30 | root |
组件版本
| 组件 | 版本 |
|---|---|
| java | 1.8 |
| Hadoop | 3.1.3 |
| Hive | 3.1.2 |
| Mysql | 5.7 |
| zookeeper | 3.4.6 |
| HBase | 2.2.3 |
8.1 解压所需压缩包并重命名
[root@master ~]# tar -zxvf /opt/software/hbase-2.2.3-bin.tar.gz -C /opt/module/
[root@master ~]# mv /opt/module/hbase-2.2.3/ /opt/module/hbase
8.2 配置环境变量
所有节点添加
方法1:
vim /etc/profile
#添加以下内容
#hbase
export HBASE_HOME=/opt/module/hbase
export PATH=PATH:HBASE_HOME/bin
:wq保存退出
方法2:
添加环境变量:
刷新生效:
source /etc/profile
8.3 配置hbase.env.sh和hbase-site.xml和regionservers三个主要配置文件
8.3.1 修改hbase.env.sh
[root@master ~]# cd $HBASE_HOME/conf
[root@master conf]# vi hbase-env.sh
配置修改内容如下
export JAVA_HOME=/opt/module/jdk #28行
export HBASE_CLASSPATH=/opt/module/hbase/conf #31行
export HADOOP_HOME=/opt/module/hadoop #手动添加
#是否使用hbase自带的zookeeper服务(默认true使用)
export HBASE_MANAGES_ZK=false #126行
8.3.2 修改 hbase-site.xml
[root@master conf]# pwd
/opt/module/hbase/conf
[root@master conf]# vi hbase-site.xml
新增配置如下:
<configuration>
<property>
<!--hbase.rootdir中主机和端口号需要与$HADOOP_HOME/etc/hadoop/core-site.xml文件中fs.default.name的主机名和端口号相同-->
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<!--HBase的运行模式。false是单机模式,true是分布式模式。若为false,HBase和Zookeeper会运行在同一个JVM里面。默认: false-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<!--默认2181-->
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<!--使用本地文件系统设置为false,使用hdfs设置为true-->
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
8.3.3 配置 regionservers
修改成自己的集群节点名称
[root@master conf]# cat regionservers
master
slave1
slave2
8.4 更换jar包
[root@master conf]# rm -rf /opt/module/hbase/lib/client-facing-thirdparty/slf4j-*
[root@master conf]# cp HADOOP_HOME/share/hadoop/common/lib/slf4j-*HBASE_HOME/lib/client-facing-thirdparty
查看替换过后的jar包:
[root@master conf]# ll $HBASE_HOME/lib/client-facing-thirdparty | grep slf4j-*
-rw-r--r-- 1 root root 41203 Jan 6 14:06 slf4j-api-1.7.25.jar
-rw-r--r-- 1 root root 12244 Jan 6 14:06 slf4j-log4j12-1.7.25.jar
8.5 分发文件至子节点
切记子节点环境没有配置的话也要进行分发
[root@master ~]# scp -r /opt/module/hbase/ root@slave1:/opt/module/
[root@master ~]# scp -r /opt/module/hbase/ root@slave2:/opt/module/
[root@master ~]# scp /etc/profile root@slave1:/etc/profile
profile 100% 2481 7.9MB/s 00:00
[root@master ~]# scp /etc/profile root@slave2:/etc/profile
profile 100% 2481 7.9MB/s 00:00
:warning: 分发完环境变量后记住要重新刷新载入环境变量
8.6 启动服务
前提:需要先启动zookeeper集群,如果没有启动则重启zookeeper服务
[root@master ~]# start-hbase.sh
查看进程:
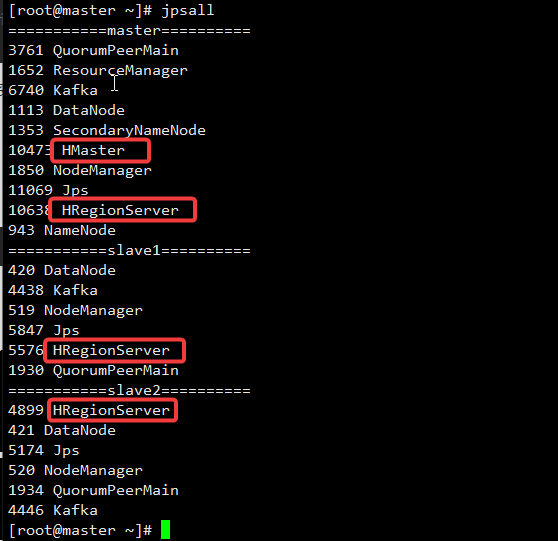
停止hbase:
stop_hbase.sh
启动客户端:
hbase shell
网页访问地址:
注: 如果是docker容器环境,需要添加端口映射,开放外部16010端口
http://master:16010
9.hbase基本命令:
1、查看所有命令
help
2、查看指定命令的用法
help 'create'
3、创建一张表
#create '表名','列名'(column family)
create 'test','cf'
# 创建指定namespace目录下面的表;所有的表名左边要加上namespace,如果不加,默认是default
create 'mydata:test','cf'
4、查看表结构
#list 表名
list 'test'
#描述这张表
describe 'test'
5、插入数据
# put 表名,键(主键),列的名字,值
put 'test','01','cf:name','zhangsan'
put 'test','01','cf:age','18'
# 指定namespace的表插入记录
put 'mydata:test','01','cf:name','zhangsan'
put 'mydata:test','01','cf:age','18'
6、查询
# 查询所有记录
# scan 表名
scan 'test'
# 扫描表的记录
scan 'mydata:test'
# 查询所有记录(根据主键查询)
# get 表名,键
get 'test','01'
7、删除表
#disable 表名
disable 'test'
#drop ‘表名’
drop 'test'
8、退出客户端
quit
exit
hbase查看命名空间:
hbase> list_namespace
结果:
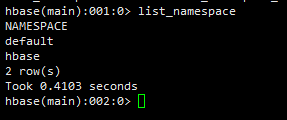
9.HBase Shell 操作
9.1 基本操作
1)进入 HBase 客户端命令行
[root@master module]# hbase shell
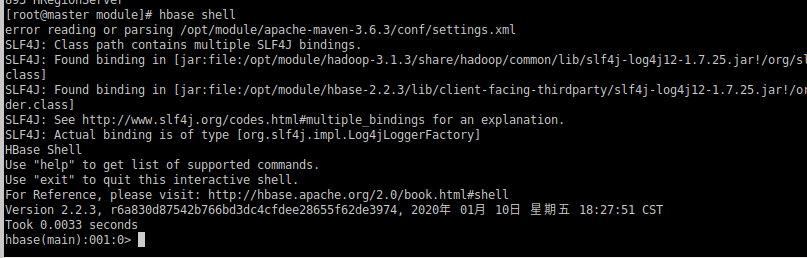
2)查看帮助命令
能够展示 HBase 中所有能使用的命令,主要使用的命令有 namespace 命令空间相关, DDL 创建修改表格,DML 写入读取数据。
hbase(main):001:0> help
9.2 namespace
9.2.1 创建命名空间
使用特定的 help 语法能够查看命令如何使用。
hbase(main):002:0> help 'create_namespace'
Create namespace; pass namespace name,
and optionally a dictionary of namespace configuration.
Examples:
hbase> create_namespace 'ns1'
hbase> create_namespace 'ns1', {'PROPERTY_NAME'=>'PROPERTY_VALUE'}
9.2.2 创建命名空间 bigdata
hbase(main):003:0> create_namespace 'bigdata'
Took 0.7499 seconds
9.2.3 查看所有的命名空间
hbase(main):004:0> list_namespace
NAMESPACE
bigdata
default
hbase
3 row(s)
Took 0.0889 seconds
9.2.4 删除命名空间
drop_namespace 'namespace_name'
9.3 DDL
DDL是数据定义语言的缩写,定义了不同的数据段、数据库、表、列、索引等数据库对象
9.3.1 创建表
在 bigdata 命名空间中创建表格 student,两个列族。info 列族数据维护的版本数为 5 个, 如果不写默认版本数为 1。
hbase(main):007:0> create 'bigdata:student', {NAME => 'info',VERSIONS => 5}, {NAME => 'msg'}
Created table bigdata:student
Took 1.3605 seconds
=> Hbase::Table - bigdata:student
参数解释:
这条命令是用来在 HBase 中创建一个名为 bigdata:student 的表,具有两个列族:info 和 msg。
bigdata是命名空间,用于组织表以防止命名冲突。student是表名。{NAME => 'info', VERSIONS => 5}:定义了一个名为info的列族,它可以存储最多 5 个版本的数据。{NAME => 'msg'}:定义了一个名为msg的列族,它的版本数未指定,将使用 HBase 的默认设置。
这个命令的作用是创建一个包含 info 和 msg 两个列族的表,允许每个列族存储多个版本的数据。
如果创建表格只有一个列族,没有列族属性,可以简写。
如果不写命名空间,使用默认的命名空间 default。
hbase:009:0> create 'student1','info'
9.3.2 查看表
查看表有两个命令:list 和 describe
list:查看所有的表名
hbase(main):008:0> list
TABLE
bigdata:student
1 row(s)
Took 0.0262 seconds
=> ["bigdata:student"]
describe:查看一个表的详情
hbase(main):011:0> describe 'bigdata:student'
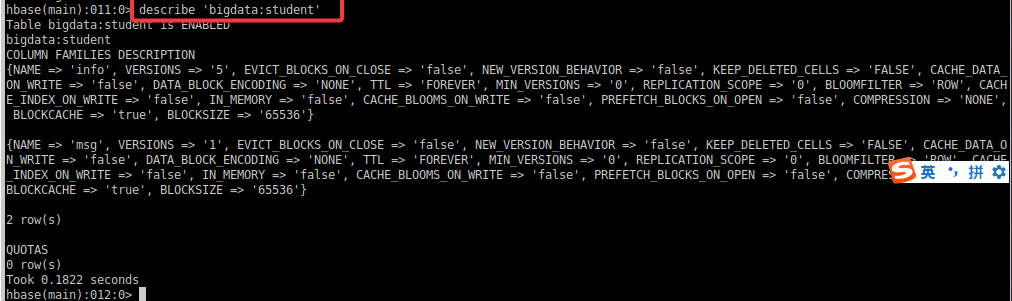
9.3.3 修改表
表名创建时写的所有和列族相关的信息,都可以后续通过 alter 修改,包括增加删除列 族。
(1)增加列族和修改信息都使用
覆盖的方法
hbase(main):013:0> alter 'bigdata:student', {NAME => 'f1',VERSIONS => 3}
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.4018 seconds
修改结果:
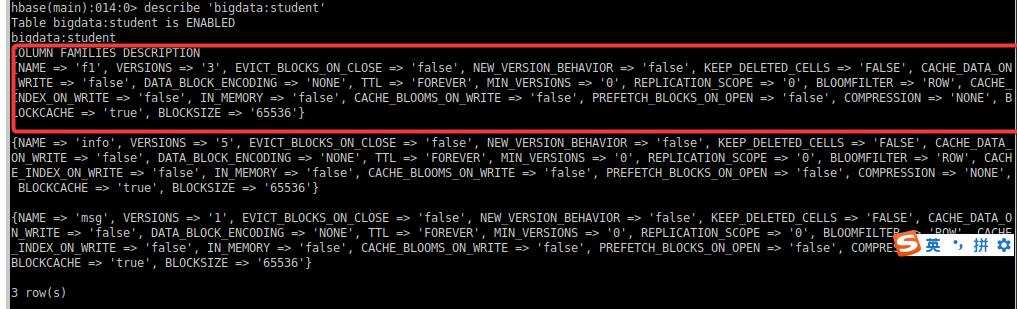
(2)删除信息使用特殊的语法
方法1:
hbase(main):016:0> alter 'bigdata:student', NAME => 'f1' , METHOD => 'delete'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.3287 seconds
方法2::star:
hbase(main):017:0> alter 'bigdata:student' , 'delete' => 'f1'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.1905 seconds
总结:
第一个指令 alter 'bigdata:student', NAME => 'f1', METHOD => 'delete' 是用于从 bigdata 命名空间中的 student 表中删除指定的列族 f1。这个指令使用了 NAME => 'f1', METHOD => 'delete' 的语法来指定要删除的列族。
第二个指令 alter 'bigdata:student', 'delete' => 'f1' 则是用于从 bigdata 命名空间中的 student 表中删除列族 f1。这个指令使用了 'delete' => 'f1' 的语法来指定要删除的列族。
总的来说,这两个指令的作用是一样的,都是用于删除表中的指定列族,只是语法略有不同。
9.3.4 删除表
shell 中删除表格,需要先将表格状态设置为不可用。
hbase(main):019:0> disable 'bigdata:student'
Took 0.8051 seconds
hbase(main):020:0> drop 'bigdata:student'
Took 0.4800 seconds
9.4 DML
DML是数据操作语言(Data Manipulation Language)的缩写,是一种用于管理数据库中数据的语言。DML允许用户查询、插入、更新和删除数据库中的数据。常见的DML命令包括SELECT(查询数据)、INSERT(插入数据)、UPDATE(更新数据)和DELETE(删除数据)。通过使用DML,用户可以有效地操作数据库中的数据,实现对数据的增删改查操作。与DML相对的是DDL(数据定义语言),DDL用于定义数据库的结构,例如创建表、定义索引等。在数据库操作中,DML和DDL是两个重要的概念,分别用于处理数据和定义数据结构。
9.4.1 写入数据
在 HBase 中如果想要写入数据,只能添加结构中最底层的 cell。可以手动写入时间戳指 定 cell 的版本,推荐不写默认使用当前的系统时间。
hbase(main):026:0> put 'bigdata:student','1001','info:name','zhangsan'
hbase(main):027:0> put 'bigdata:student','1001','info:name','lisi'
hbase(main):028:0> put 'bigdata:student','1001','info:age','18'
如果重复写入相同 rowKey,相同列的数据,会写入多个版本进行覆盖。
9.4.2 读取数据
读取数据的方法有两个:get 和 scan。
get 最大范围是一行数据,也可以进行列的过滤,读取数据的结果为多行 cell。
hbase(main):035:0> get 'bigdata:student','1001'
COLUMN CELL
info:age timestamp=1708486781447, value=18
info:name timestamp=1708486751789, value=lisi
1 row(s)
Took 0.0114 seconds
hbase(main):036:0> get 'bigdata:student','1001' , {COLUMN => 'info:name'}
COLUMN CELL
info:name timestamp=1708486751789, value=lisi
1 row(s)
Took 0.0213 seconds
也可以修改读取 cell 的版本数,默认读取一个。最多能够读取当前列族设置的维护版本 数。
hbase(main):037:0> get 'bigdata:student','1001' , {COLUMN => 'info:name', VERSIONS => 6}
COLUMN CELL
info:name timestamp=1708486751789, value=lisi
info:name timestamp=1708486725660, value=zhangsan
1 row(s)
Took 0.0057 seconds
scan 是扫描数据,能够读取多行数据,不建议扫描过多的数据,推荐使用 startRow 和 stopRow 来控制读取的数据,默认范围左闭右开。
hbase(main):038:0> scan 'bigdata:student', {STARTROW => '1001',STOPROW => '1002'}
ROW COLUMN+CELL
1001 column=info:age, timestamp=1708486781447, value=18
1001 column=info:name, timestamp=1708486751789, value=lisi
1 row(s)
Took 0.0392 seconds
实际开发中使用 shell 的机会不多,所有丰富的使用方法到 API 中介绍。
9.4.3 删除数据
删除数据的方法有两个:delete 和 deleteall。
delete 表示删除一个版本的数据,即为 1 个 cell,不填写版本默认删除最新的一个版本。
hbase(main):039:0> delete 'bigdata:student','1001','info:name'
Took 0.0302 seconds
deleteall 表示删除所有版本的数据,即为当前行当前列的多个 cell。
(执行命令会标记 数据为要删除,不会直接将数据彻底删除,删除数据只在特定时期清理磁盘时进行)
hbase(main):040:0> deleteall 'bigdata:student' ,'1001','info:name'
Took 0.0099 seconds
10. HBase API
10.1 环境准备
新建项目后在 pom.xml 中添加依赖:
注意:会报错 javax.el 包不存在,是一个测试用的依赖,不影响使用
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.4.11</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.1-b06</version>
</dependency>
</dependencies>
10.2 创建连接
根据官方 API 介绍,HBase 的客户端连接由 ConnectionFactory 类来创建,用户使用完成 之后需要手动关闭连接。同时连接是一个重量级的,推荐一个进程使用一个连接,对 HBase 的命令通过连接中的两个属性 Admin 和 Table 来实现。
10.2.1 单线程创建连接
方案1:
package hbase_test
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{AsyncConnection, Connection, ConnectionFactory}
import java.io.IOException
import java.util.concurrent.CompletableFuture
object HBaseConnect {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf = new Configuration()
// 2. 添加配置参数
conf.set("hbase.zookeeper.quorum", "master,slave1,slave2")
// 3. 创建 hbase 的连接
// 默认使用同步连接
val connection: Connection = ConnectionFactory.createConnection(conf)
// 可以使用异步连接
// 主要影响后续的 DML 操作
val asyncConnection: CompletableFuture[AsyncConnection] = ConnectionFactory.createAsyncConnection(conf)
// 4. 使用连接
println(connection)
// 5. 关闭连接
connection.close()
}
}
方案2:
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{HBaseConfiguration, HConstants}
import org.apache.hadoop.hbase.client.{ConnectionFactory, Connection}
object SingleThreadConnectionExample {
// HBase 连接配置
val conf: Configuration = {
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set(HConstants.ZOOKEEPER_QUORUM, "localhost") // 设置 Zookeeper 地址
hbaseConf
}
// 创建 HBase 连接
val connection: Connection = ConnectionFactory.createConnection(conf)
def main(args: Array[String]): Unit = {
// 在这里使用 connection 对象执行操作
// 例如:connection.getTable(tableName),connection.getAdmin() 等
// 关闭连接
connection.close()
}
}
10.2.2 多线程创建连接:warning:待测试
使用类单例模式,确保使用一个连接,可以同时用于多个线程。
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{HBaseConfiguration, HConstants}
import org.apache.hadoop.hbase.client.ConnectionFactory
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Future
object MultiThreadConnectionExample {
// HBase 连接配置
val conf: Configuration = {
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set(HConstants.ZOOKEEPER_QUORUM, "localhost") // 设置 Zookeeper 地址
hbaseConf
}
def createConnection(): Future[Unit] = Future {
// 创建 HBase 连接
val connection = ConnectionFactory.createConnection(conf)
// 在这里使用 connection 对象执行操作
// 例如:connection.getTable(tableName),connection.getAdmin() 等
// 关闭连接
connection.close()
}
def main(args: Array[String]): Unit = {
// 创建多个连接
val connections: Seq[Future[Unit]] = (1 to 5).map(_ => createConnection())
// 等待所有连接创建完成
val allConnections: Future[Seq[Unit]] = Future.sequence(connections)
// 等待所有连接创建完成后执行其他操作
allConnections.onComplete { _ =>
// 所有连接创建完成后的操作
println("所有连接创建完成")
}
}
}
在 resources 文件夹中创建配置文件 hbase-site.xml,添加以下内容(可选)
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
</configuration>
10.3 DDL
创建 HBaseDDL 类,添加静态方法即可作为工具类
官网API手册 https://hbase.apache.org/2.3/apidocs/index.html
10.3.1.创建命名空间(namespace)
方案1:
package com.hj_test
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{HBaseConfiguration, NamespaceDescriptor, NamespaceExistException}
import org.apache.hadoop.hbase.client.{Admin, Connection, ConnectionFactory}
import java.io.IOException
/**
* Connection: 通过ConnectionFactory获取,是重量级实现
* Table: 主要负责DML操作
* Admin: 只要负责DDl操作
*/
object CreateNameSpace {
//连接hbase
private val connection: Connection = {
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "bigdata1,bigdata2,bigdata3")
try {
ConnectionFactory.createConnection(conf)
} catch {
case e: IOException =>
e.printStackTrace()
throw e
}
}
//创建的命名空间名字
def main(args: Array[String]): Unit = {
createNameSpace("bigdata")
}
/**
* 创建namespace
*/
def createNameSpace(nameSpace: String): Unit = {
//判空操作
if (nameSpace == null || nameSpace.isEmpty) {
System.err.println("nameSpace名字不能为空")
return
}
//获取Admin对象
val admin: Admin = connection.getAdmin
val builder: NamespaceDescriptor.Builder = NamespaceDescriptor.create(nameSpace)
val namespaceDescriptor: NamespaceDescriptor = builder.build()
//调用方法
try {
admin.createNamespace(namespaceDescriptor)
println(s"nameSpace 创建成功")
} catch {
case _: NamespaceExistException =>
System.err.println(s"nameSpace 已经存在")
} finally {
admin.close()
}
}
}
:star: 方案2:
package com.hj_test
import org.apache.hadoop.hbase.{HBaseConfiguration, NamespaceDescriptor, NamespaceExistException}
import org.apache.hadoop.hbase.client.{Admin, Connection, ConnectionFactory}
object CreateNamespaceDemo {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "bigdata1,bigdata2,bigdata3")
// 创建 HBase 连接
val connection: Connection = ConnectionFactory.createConnection(conf)
// 获取 Admin 对象
val admin: Admin = connection.getAdmin
// 定义要创建的命名空间名称
val nameSpaceName = "bigdata123"
// 创建命名空间描述符
val namespaceDescriptor = NamespaceDescriptor.create(nameSpaceName).build()
// 创建命名空间 (调用方法1)
// admin.createNamespace(namespaceDescriptor)
// 创建命名空间 (调用方法2)
try {
admin.createNamespace(namespaceDescriptor)
println(s"nameSpaceName 创建成功")
} catch {
case _: NamespaceExistException =>
System.err.println(s"nameSpaceName 已经存在")
} finally {
admin.close()
}
}
}
10.3.2.创建表
package com.hj_test
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Admin, ColumnFamilyDescriptorBuilder, Connection, ConnectionFactory, TableDescriptorBuilder}
import org.apache.hadoop.hbase.util.Bytes
object CreateTableDemo {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "bigdata1,bigdata2,bigdata3") // 设置 Zookeeper 地址
// 创建 HBase 连接
val connection: Connection = ConnectionFactory.createConnection(conf)
// 获取 Admin 对象
val admin: Admin = connection.getAdmin
// 定义表格信息
val tableName = TableName.valueOf("bigdata:student")
val columnFamily = Bytes.toBytes("info")
// 创建表格描述符
val tableDescriptor = TableDescriptorBuilder.newBuilder(tableName)
.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(columnFamily).build())
.build()
// 创建表格
admin.createTable(tableDescriptor)
// 关闭连接
admin.close()
connection.close()
println("表格创建成功!")
}
}
10.3.3.删除表
package com.hj_test
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Admin, Connection, ConnectionFactory}
/**
* 删除表
*/
object DeleteTableDemo {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "bigdata1,bigdata2,bigdata3") // 设置 Zookeeper 地址
// 创建 HBase 连接
val connection: Connection = ConnectionFactory.createConnection(conf)
// 获取 Admin 对象
val admin: Admin = connection.getAdmin
// 定义表格名称
val tableName = TableName.valueOf("huangjing")
// 删除表格
if (admin.tableExists(tableName)) {
admin.disableTable(tableName)
admin.deleteTable(tableName)
println("表格删除成功!")
} else {
println("要删除的表格不存在!")
}
// 关闭连接
admin.close()
connection.close()
}
}
10.3.4.判断表是否存在
package com.hj_test
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Admin, Connection, ConnectionFactory}
object TableExistsDemo {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum","bigdata1,bigdata2,bigdata3") // 设置 Zookeeper 地址
//建立连接
val connection: Connection = ConnectionFactory.createConnection(conf)
// 获取 Admin 对象
val admin:Admin = connection.getAdmin
// 定义要检查的表格名称
val tableName = TableName.valueOf("ods:lineitem_hbase")
//判断表格是否存在
val tableExists = admin.tableExists(tableName)
if (tableExists) {
println("表格存在!")
} else {
println("表格不存在!")
}
//关闭连接
admin.close()
connection.close()
}
}
10.4 DML
10.4.1 写入数据
package com.hj_test
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, Put, Table}
import org.apache.hadoop.hbase.util.Bytes
object PutDataDemo {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum","bigdata1,bigdata2,bigdata3")
// 创建 HBase 连接
val connection: Connection = ConnectionFactory.createConnection(conf)
//定义表格名称和列族名称
val tableName = TableName.valueOf("bigdata:student")
val columnFamily = Bytes.toBytes("info")
// 创建 Table 对象
val table: Table = connection.getTable(tableName)
//定义要插入的数据
val rowKey = "1001" //数据的行键
val qualifier = "qualifier1" //代表列限定符
val value = "huangjing" //代表要插入的值
// 创建 Put 对象,并添加数据
val put = new Put(Bytes.toBytes(rowKey))
put.addColumn(columnFamily,Bytes.toBytes(qualifier),Bytes.toBytes(value))
// 插入数据
table.put(put)
//关闭连接
table.close()
connection.close()
println("数据插入成功!")
}
}
案例1:创建hbase相关表,创建200条随机数据
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, Put}
import org.apache.hadoop.hbase.util.Bytes
import scala.util.Random
object CreateDataExample {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "bigdata1,bigdata2,bigdata3") // 设置 Zookeeper 地址
// 创建 HBase 连接
val connection: Connection = ConnectionFactory.createConnection(conf)
// 定义表格名称
val tableName = TableName.valueOf("example_table")
// 创建表格连接
val table = connection.getTable(tableName)
// 定义要插入的数据的列族和列限定符
val columnFamily = Bytes.toBytes("cf")
val qualifier = Bytes.toBytes("qualifier")
// 随机生成数据
val random = new Random()
// 创建 200 条数据并插入表格
for (i <- 1 to 200) {
val rowKey = s"row_$i"
val value = random.nextInt(100).toString
val put = new Put(Bytes.toBytes(rowKey))
put.addColumn(columnFamily, qualifier, Bytes.toBytes(value))
table.put(put)
}
println("200 条数据插入成功!")
// 关闭连接
table.close()
connection.close()
}
}
10.4.2 读取指定数据
package com.hj_test
import org.apache.hadoop.hbase.{HBaseConfiguration,TableName}
import org.apache.hadoop.hbase.client.{ConnectionFactory,Connection,Get,Result,Table}
import org.apache.hadoop.hbase.util.Bytes
object GetDataDemo {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum","bigdata1,bigdata2,bigdata3")
// 创建 HBase 连接
val connection : Connection = ConnectionFactory.createConnection(conf)
// 定义表格名称和列族名称
val tableName = TableName.valueOf("bigdata:student")
val columnFamily = Bytes.toBytes("info")
// 创建 Table 对象
val table : Table = connection.getTable(tableName)
// 定义要读取的数据的行键和列限定符
val rowKey = "1001"
val qualifier = "qualifier1"
// 创建 Get 对象,并设置要读取的数据的行键
val get = new Get(Bytes.toBytes(rowKey))
// 通过 Get 对象获取数据
val result: Result = table.get(get)
// 从 Result 对象中获取指定列族和列限定符的值
val valueBytes: Array[Byte] = result.getValue(columnFamily, Bytes.toBytes(qualifier))
// 将字节数组转换为字符串
val value: String = Bytes.toString(valueBytes)
println(s"读取的值为:$value")
// 关闭连接
table.close()
connection.close()
}
}
10.4.3 scan 扫描全部数据
package com.hj_test
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, Get, Result, ResultScanner, Scan, Table}
import org.apache.hadoop.hbase.util.Bytes
/**
* 读取数据 读取对应的一行中的某一列
*
* namespace 命名空间名称
* tableName 表格名称
* rowKey 主键
* columnFamily 列族名称
* columnName 列名
*/
object ScanDataDemo {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "bigdata1,bigdata2,bigdata3")
// 创建 HBase 连接
val connection: Connection = ConnectionFactory.createConnection(conf)
// 定义表格名称和列族名称
val tableName = TableName.valueOf("bigdata:student")
// 创建 Table 对象
val table: Table = connection.getTable(tableName)
// 创建 Scan 对象
val scan = new Scan()
// 获取扫描结果的 ResultScanner 对象
val scanner : ResultScanner = table.getScanner(scan)
// 遍历扫描结果并打印数据 (使用表格对象的 getScanner 方法获取一个 ResultScanner 对象,用于遍历扫描结果。)
scanner.forEach {result =>
val rowKey = Bytes.toString(result.getRow)
result.rawCells().foreach { cell =>
val family = Bytes.toString(cell.getFamilyArray, cell.getFamilyOffset, cell.getFamilyLength)
val qualifier = Bytes.toString(cell.getQualifierArray, cell.getQualifierOffset, cell.getQualifierLength)
val value = Bytes.toString(cell.getValueArray, cell.getValueOffset, cell.getValueLength)
println(s"Row key: rowKey, Family:family, Qualifier: qualifier, Value:value")
}
}
// 关闭 ResultScanner 对象
scanner.close()
// 关闭连接
table.close()
connection.close()
}
}
10.4.4 删除表数据
package com.hj_test
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, ResultScanner, Scan, Table}
import org.apache.hadoop.hbase.util.Bytes
object ScanDataDemo {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "bigdata1,bigdata2,bigdata3")
// 创建 HBase 连接
val connection: Connection = ConnectionFactory.createConnection(conf)
// 定义表格名称
val tableName = TableName.valueOf("bigdata:student")
// val tableName = TableName.valueOf("ods:lineitem_hbase")
// 创建 Table 对象
val table: Table = connection.getTable(tableName)
// 创建 Scan 对象
val scan = new Scan()
// 获取扫描结果的 ResultScanner 对象
val scanner: ResultScanner = table.getScanner(scan)
// 遍历扫描结果并打印数据 (使用表格对象的 getScanner 方法获取一个 ResultScanner 对象,用于遍历扫描结果。)
scanner.forEach { result =>
val rowKey = Bytes.toString(result.getRow)
result.rawCells().foreach { cell =>
val family = Bytes.toString(cell.getFamilyArray, cell.getFamilyOffset, cell.getFamilyLength)
val qualifier = Bytes.toString(cell.getQualifierArray, cell.getQualifierOffset, cell.getQualifierLength)
val value = Bytes.toString(cell.getValueArray, cell.getValueOffset, cell.getValueLength)
println(s"Row key: rowKey, Family:family, Qualifier: qualifier, Value:value")
}
}
// 关闭 ResultScanner 对象
scanner.close()
// 关闭连接
table.close()
connection.close()
}
}
10.4.5 过滤扫描
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, Scan}
import org.apache.hadoop.hbase.filter.{CompareFilter, FilterList, SingleColumnValueFilter}
import org.apache.hadoop.hbase.util.Bytes
object ScanWithFilterDemo {
def main(args: Array[String]): Unit = {
// HBase 连接配置
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "bigdata1,bigdata2,bigdata3") // 设置 Zookeeper 地址
// 创建 HBase 连接
val connection: Connection = ConnectionFactory.createConnection(conf)
// 定义表格名称
val tableName = TableName.valueOf("ods:lineitem_hbase")
// 创建表格扫描器
val table = connection.getTable(tableName)
val scan = new Scan()
// 创建过滤器列表
val filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL)
// 创建列值过滤器
val valueFilter = new SingleColumnValueFilter(
Bytes.toBytes("info"), // 列族名称
Bytes.toBytes("create_time"), // 列限定符名称
CompareFilter.CompareOp.EQUAL, // 比较运算符
Bytes.toBytes("value")) // 目标值
filterList.addFilter(valueFilter)
// 设置扫描器的过滤器
scan.setFilter(filterList)
// 执行扫描
val scanner = table.getScanner(scan)
// 遍历扫描结果
val iterator = scanner.iterator()
while (iterator.hasNext) {
val result = iterator.next()
// 处理扫描结果,例如输出或其他操作
println(result)
}
// 关闭连接
scanner.close()
table.close()
connection.close()
}
}