DolphinScheduler-3.1.4 海豚调度器
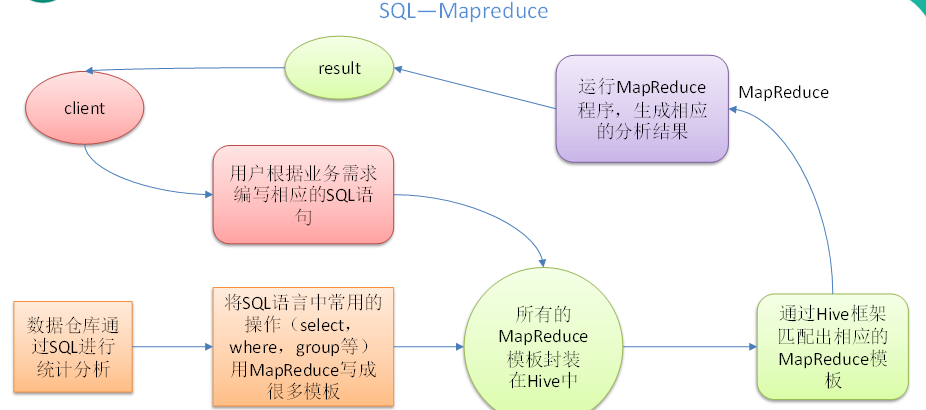
1. DolphinScheduler 简介
官网:https://dolphinscheduler.apache.org/zh-cn
1.1 DolphinScheduler 概述
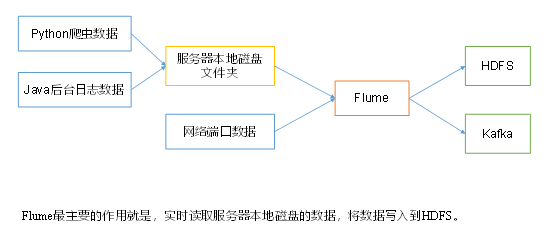
Apache DolphinScheduler 是一个分布式、易扩展的可视化 DAG 工作流任务调度平台。 致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
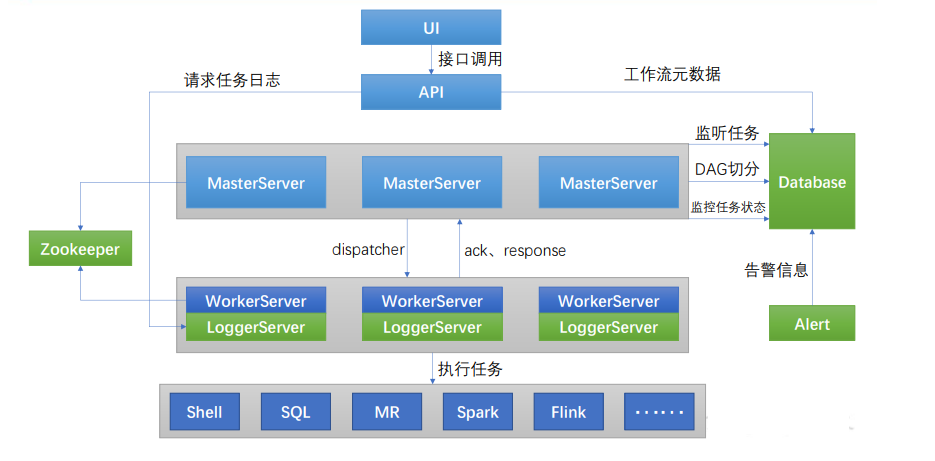
1.2 DolphinScheduler 核心架构
DolphinScheduler 的主要角色如下:
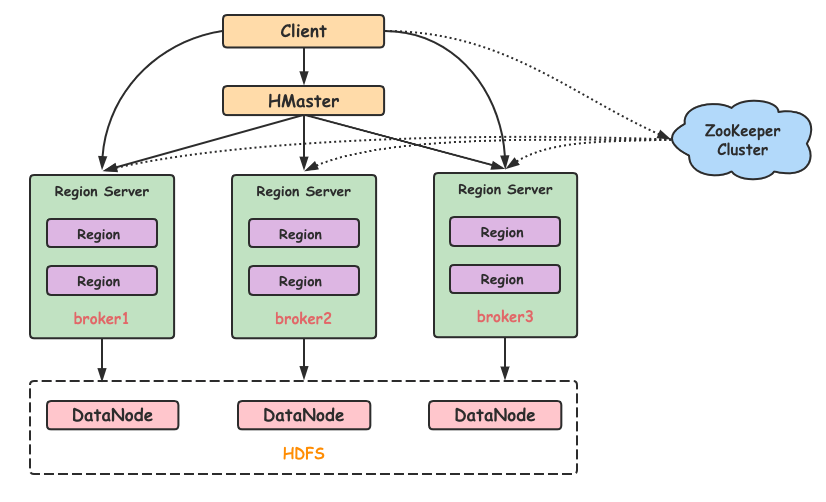
MasterServer采用分布式无中心设计理念,MasterServer 主要负责 DAG 任务切分、任 务提交、任务监控,并同时监听其它 MasterServer 和 WorkerServer 的健康状态。WorkerServer也采用分布式无中心设计理念,WorkerServer 主要负责任务的执行和提 供日志服务。ZooKeeper服务,系统中的 MasterServer 和 WorkerServer 节点都通过 ZooKeeper 来进 行集群管理和容错。Alert服务,提供告警相关服务API接口层,主要负责处理前端 UI 层的请求UI,系统的前端页面,提供系统的各种可视化操作界面。
2. DolphinScheduler 部署说明
2.1 软硬件环境要求
2.1.1 操作系统版本要求
| 操作系统 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.0 及以上 |
| CentOS | 7.0 及以上 |
| Oracle Enterprise Linux | 7.0 及以上 |
| Ubuntu LTS | 16.04 及以上 |
2.1.2 服务器硬件要求
| cpu | 内存 | 硬盘类型 | 网络 | 实例数量 |
|---|---|---|---|---|
| 4 核+ | 8 GB+ | SAS | 千兆网卡 | 1+ |
2.2 部署模式
DolphinScheduler 支持多种部署模式,包括单机模式(Standalone)、伪集群模式(PseudoCluster)、集群模式(Cluster)等
2.2.1 单机模式
单机模式(standalone)模式下,所有服务均集中于一个 StandaloneServer 进程中,并且其中内置了注册中心 Zookeeper 和数据库 H2。只需配置 JDK 环境,就可一键启动 DolphinScheduler,快速体验其功能。
2.2.2 伪集群模式
伪集群模式(Pseudo-Cluster)是在单台机器部署 DolphinScheduler 各项服务,该模式 下 master、worker、api server、logger server 等服务都只在同一台机器上。Zookeeper 和数据 库需单独安装并进行相应配置。
2.2.3 集群模式
集群模式(Cluster)与伪集群模式的区别就是在多台机器部署 DolphinScheduler 各项服 务,并且 Master、Worker 等服务可配置多个。
3. DolphinScheduler 集群模式部署
3.1 集群规划
集群模式下,可配置多个 Master 及多个 Worker。“通常可配置 2~3 个 Master`,若干个 Worker。由于集群资源有限,此处配置一个 Master,三个 Worker,集群规划如下。
| 容器环境 | ip | 服务 |
|---|---|---|
| master | 192.168.1.10 | master、worker |
| slave1 | 192.168.1.20 | worker |
| slave2 | 192.168.1.30 | worker |
3.2前置准备工作
(1)三台节点均需部署 JDK(1.8+),并配置相关环境变量。
(2)需部署数据库,支持 MySQL(5.7+)或者 PostgreSQL(8.2.15+)。
(3)需部署 Zookeeper(3.4.6+)。
(4)三台节点均需安装“进程树分析工具 psmisc`。
yum install -y psmisc
3.3 解压 DolphinScheduler 安装包
(1)上传 DolphinScheduler 安装包到 master 节点的/opt/software 目录
[root@master ~]# ll /opt/software/ |grep dolphinscheduler
-rw-rw-r-- 1 root root 672374885 May 5 2023 apache-dolphinscheduler-3.1.4-bin.tar.gz

(2)解压安装包到/opt/module/目录
注:解压目录并非最终的安装目录
[root@master module]# tar -zxvf /opt/software/apache-dolphinscheduler-3.1.4-bin.tar.gz -C /opt/module/
[root@master module]# mv apache-dolphinscheduler-3.1.4-bin/ apache-dolphinscheduler-3.1.4
3.4 创建元数据库及用户
DolphinScheduler 元数据存储在关系型数据库中,故需创建相应的数据库和用户。
(1)创建数据库
创建dolphinscheduler的元数据库,并指定编码
mysql -uroot -p123456 -e "CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;"
(2)创建用户(可选,这里我
使用root用户登录则跳过)
创建dolphinscheduler的数据库用户和密码,并限定登陆范围
mysql -uroot -p123456 -e "CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY '123456';"
查看是否创建成功:
mysql -uroot -p123456 -e "SELECT user, host FROM mysql.user WHERE user = 'dolphinscheduler';"

:warning:注意:
若出现以下错误信息,表明新建用户的密码过于简单。
错误内容:
ERROR 1819 (HY000): Your password does not satisfy the current policy
requirements
解决: 可提高密码复杂度或者执行以下命令降低 MySQL 密码强度级别。
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
(3)赋予用户相应权限
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
mysql> flush privileges;
3.5 添加MySQL驱动
将mysql-connector-java驱动(8.0.16)上传到/opt/jars,并移动到 DolphinScheduler 的每个模块的 libs 目录下,其中包括 api-server/libs和 alert-server/libs 和 “master-server/libs和worker-server/libs和tools/libs`
[root@master apache-dolphinscheduler-3.1.4]# cp /opt/software/jars/mysql-connector-java-8.0.16.jar api-server/libs/
[root@master apache-dolphinscheduler-3.1.4]# cp /opt/software/jars/mysql-connector-java-8.0.16.jar alert-server/libs/
[root@master apache-dolphinscheduler-3.1.4]# cp /opt/software/jars/mysql-connector-java-8.0.16.jar master-server/libs/
[root@master apache-dolphinscheduler-3.1.4]# cp /opt/software/jars/mysql-connector-java-8.0.16.jar worker-server/libs/
[root@master apache-dolphinscheduler-3.1.4]# cp /opt/software/jars/mysql-connector-java-8.0.16.jar tools/libs/
3.6 修改dolphinscheduler_env.sh配置文件:
文件 ./bin/env/dolphinscheduler_env.sh 描述了下列配置:
- DolphinScheduler 的数据库配置,将username和password改成你在上一步中设置的用户名和密码
- 一些任务类型外部依赖路径或库文件,如 JAVA_HOME 和 SPARK_HOME都是在这里定义的
- 注册中心zookeeper
- 服务端相关配置,比如缓存,时区设置等
如果您不使用某些任务类型,您可以忽略任务外部依赖项,但您必须根据您的环境更改 JAVA_HOME、注册中心和数据库相关配置。
[root@master apache-dolphinscheduler-3.1.4]# vim /opt/module/apache-dolphinscheduler-3.1.4/bin/env/dolphinscheduler_env.sh
修改配置内容如下:
确保所有节点都有spark服务
# JAVA_HOME, will use it to start DolphinScheduler server
# 改为自己的JDK路径
export JAVA_HOME={JAVA_HOME:-/opt/module/jdk1.8.0_162}
# Database related configuration, set database type, username and password
# MySQL数据库连接信息
export DATABASE={DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE={DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://192.168.1.10:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true"
export SPRING_DATASOURCE_USERNAME={SPRING_DATASOURCE_USERNAME:-"root"}
export SPRING_DATASOURCE_PASSWORD={SPRING_DATASOURCE_PASSWORD:-"123456"}
# DolphinScheduler server related configuration
# 不用修改
export SPRING_CACHE_TYPE={SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE={SPRING_JACKSON_TIME_ZONE:-UTC}
export MASTER_FETCH_COMMAND_NUM={MASTER_FETCH_COMMAND_NUM:-10}
# Registry center configuration, determines the type and link of the registry center
# zookeeper集群信息
export REGISTRY_TYPE={REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING={REGISTRY_ZOOKEEPER_CONNECT_STRING:-master:2181,slave1:2181,slave2:2181}
# Tasks related configurations, need to change the configuration if you use the related tasks.
# 对已有可以正常配置,没有的保持默认即可(SPARK_HOME1和SPARK_HOME2全改成本地spark目录,不然后面运行spark项目报错,确保所有节点都有spark服务)
export HADOOP_HOME={HADOOP_HOME:-/opt/module/hadoop-3.1.3}
export HADOOP_CONF_DIR={HADOOP_CONF_DIR:-/opt/module/hadoop-3.1.3/etc/hadoop}
export SPARK_HOME1={SPARK_HOME1:-/opt/module/spark-3.1.1-yarn}
export SPARK_HOME2={SPARK_HOME2:-/opt/module/spark-3.1.1-yarn}
export PYTHON_HOME={PYTHON_HOME:-/usr/bin/python}
export HIVE_HOME={HIVE_HOME:-/opt/module/hive-3.1.2}
export FLINK_HOME={FLINK_HOME:-/opt/module/flink-1.14.0}
export DATAX_HOME={DATAX_HOME:-/usr/local/datax}
export SEATUNNEL_HOME={SEATUNNEL_HOME:-/opt/soft/seatunnel}
export CHUNJUN_HOME={CHUNJUN_HOME:-/opt/soft/chunjun}
export PATH=HADOOP_HOME/bin:SPARK_HOME1/bin:SPARK_HOME2/bin:PYTHON_HOME/bin:JAVA_HOME/bin:HIVE_HOME/bin:FLINK_HOME/bin:DATAX_HOME/bin:$PATH
扩展:
参数:
export JAVA_HOME=${JAVA_HOME:-/opt/module/jdk1.8.0_162}
解释:
JAVA_HOME=${JAVA_HOME:-/opt/module/jdk1.8.0_162}: 这是一个变量赋值语句,它的含义是如果 JAVA_HOME 已经被设置为某个值,就使用该值,否则将其设置为 /opt/module/jdk1.8.0_162。
修改成功如下图:

3.7 初始化元数据
# 切换到apache-dolphinscheduler-3.1.4-bin目录下,执行命令
[root@master apache-dolphinscheduler-3.1.4]# sh tools/bin/upgrade-schema.sh
初始化成功结果如下:

3.8 修改安装环境配置
完成基础环境和元数据库初始化的准备后,需要根据你的机器环境修改配置文件。配置文件可以在目录 bin/env 中找到,他们分别是 install_env.sh 和 dolphinscheduler_env.sh。
(1) 修改
install_env.sh文件
文件 install_env.sh 描述了哪些机器将被安装 DolphinScheduler 以及每台机器对应安装哪些服务。您可以在路径 bin/env/install_env.sh 中找到此文件,可通过以下方式更改env变量,export
[root@master apache-dolphinscheduler-3.1.4]# vim bin/env/install_env.sh
修改配置如下:
# ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# A comma separated list of machine hostname or IP would be installed DolphinScheduler,
# 包含集群中所有节点的 IP 地址或主机名,用逗号分隔
ips="master,slave1,slave2"
# SSH 连接的端口
sshPort={sshPort:-"22"}
# Example for hostnames: masters="ds1,ds2", Example for IPs: masters="192.168.8.1,192.168.8.2"
#masters={masters:-"ds1,ds2"}
# DolphinScheduler 的主节点,可以是单节点或多节点
masters="master"
#workers={workers:-"ds1:default,ds2:default,ds3:default,ds4:default,ds5:default"}
# DolphinScheduler 的工作节点
workers="master:default,slave1:default,slave2:default"
#alertServer={alertServer:-"ds3"}
# DolphinScheduler 的报警服务器
alertServer="slave2"
# Example for hostname: apiServers="ds1", Example for IP: apiServers="192.168.8.1"
#apiServers={apiServers:-"ds1"}
# DolphinScheduler 的 API 服务器
apiServers="master"
# DolphinScheduler 的最终安装路径,如果不存在,脚本会自动创建
installPath={installPath:-"/usr/local/dolphinscheduler-3.1.4"}
#deployUser={deployUser:-"dolphinscheduler"}
# 部署 DolphinScheduler 的用户 , 没有则使用root用户
deployUser={deployUser:-"root"}
# Zookeeper 的根目录,DolphinScheduler 默认使用 Zookeeper 作为注册中心
zkRoot=${zkRoot:-"/dolphinscheduler"}
最终如下(参考):

3.9 配置ds资源中心
如果未配置,则会出现以下以下问题:


:warning: 上传失败,提示存储未启用。
本地资源配置:
:one:修改api-server/conf/common.properties配置文件
[root@bigdata1 ~]# vim /opt/module/dolphinscheduler-3.1.4/api-server/conf/common.properties
修改成如下配置:
指定数据目录,需手动创建:
:warning:注意:这里的指定数据存储目录是在hdfs层上,也就是hadoop上
如果到后面创建租户时报错如下:
排查方向可以从hdfs上查看,可能是存储目录没有创建,或者没有权限

1.授权
hdfs dfs -chmod -R 777 /
2.创建存储目录
hdfs dfs -mkdir -p /root/dolphinscheduler
[root@bigdata1 dolphinscheduler]# grep -Ev "^#|^" api-server/conf/common.properties
data.basedir.path=/root/dolphinscheduler
resource.storage.type=HDFS
resource.storage.upload.base.path=/root/dolphinscheduler
resource.aws.access.key.id=minioadmin
resource.aws.secret.access.key=minioadmin
resource.aws.region=cn-north-1
resource.aws.s3.bucket.name=dolphinscheduler
resource.aws.s3.endpoint=http://localhost:9000
resource.alibaba.cloud.access.key.id=<your-access-key-id>
resource.alibaba.cloud.access.key.secret=<your-access-key-secret>
resource.alibaba.cloud.region=cn-hangzhou
resource.alibaba.cloud.oss.bucket.name=dolphinscheduler
resource.alibaba.cloud.oss.endpoint=https://oss-cn-hangzhou.aliyuncs.com
resource.hdfs.root.user=hdfs
resource.hdfs.fs.defaultFS=hdfs://bigdata1:9000
hadoop.security.authentication.startup.state=false
java.security.krb5.conf.path=/opt/krb5.conf
login.user.keytab.username=hdfs-mycluster@ESZ.COM
login.user.keytab.path=/opt/hdfs.headless.keytab
kerberos.expire.time=2
resource.manager.httpaddress.port=8088
yarn.resourcemanager.ha.rm.ids=192.168.xx.xx,192.168.xx.xx
yarn.application.status.address=http://ds1:%s/ws/v1/cluster/apps/%s
yarn.job.history.status.address=http://ds1:19888/ws/v1/history/mapreduce/jobs/%s
datasource.encryption.enable=false
datasource.encryption.salt=!@#%^&*
data-quality.jar.name=dolphinscheduler-data-quality-dev-SNAPSHOT.jar
support.hive.oneSession=false
sudo.enable=true
setTaskDirToTenant.enable=false
development.state=false
alert.rpc.port=50052
conda.path=/opt/anaconda3/etc/profile.d/conda.sh
task.resource.limit.state=false
ml.mlflow.preset_repository=https://github.com/apache/dolphinscheduler-mlflow
ml.mlflow.preset_repository_version="main"
最终如下(参考):

:two:worker-server/conf/common.properties
vim /opt/module/dolphinscheduler-3.1.4/worker-server/conf/common.properties
修改如:one:一致
3.10 安装DolphinScheduler
1.启动zookeeper集群
方案1:脚本启动(需要提前准备)
[root@master apache-dolphinscheduler-3.1.4]# zk.sh start
=======启动zookeeper集群==============
---------------启动master-------------
ZooKeeper JMX enabled by default
Using config: /opt/module/apache-zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------------启动slave1-------------
ZooKeeper JMX enabled by default
Using config: /opt/module/apache-zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------------启动slave2-------------
ZooKeeper JMX enabled by default
Using config: /opt/module/apache-zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@master apache-dolphinscheduler-3.1.4]# jpsall
===========master==========
1122 Jps
1027 QuorumPeerMain
===========slave1==========
553 QuorumPeerMain
651 Jps
===========slave2==========
546 QuorumPeerMain
636 Jps
方案2:所有节点指令启动服务
/opt/module/zookeeper/bin/zkServer.sh start
2.使用上面创建的部署用户运行以下命令完成部署,部署后的运行日志将存放在 安装目录下的logs 文件夹内
[root@master apache-dolphinscheduler-3.1.4]# sh bin/install.sh
注意:
第一次部署的话,可能出现 5 次sh: bin/dolphinscheduler-daemon.sh: No such file or directory相关信息,为非重要信息直接忽略即可。
成功结果如下:

(不用手动分发到子节点,运行脚本后会自动分发到子节点并启动服务)
查看进程状态:
[root@master apache-dolphinscheduler-3.1.4]# jpsall
===========master==========
1442 WorkerServer
1027 QuorumPeerMain
1413 MasterServer
1480 ApiApplicationServer
1820 Jps
===========slave1==========
553 QuorumPeerMain
894 Jps
766 WorkerServer
===========slave2==========
546 QuorumPeerMain
795 AlertServer
956 Jps
764 WorkerServer
结果:

3.11 启停命令
第一次安装后会自动启动所有服务的,如有服务问题或者后续需要启停,命令如下。下面的操作脚本都在dolphinScheduler安装目录bin下。
前提是先启动zookeeper服务
# 一键停止集群所有服务
sh /usr/local/dolphinscheduler-3.1.4/bin/stop-all.sh
# 一键开启集群所有服务
sh /usr/local/dolphinscheduler-3.1.4/bin/start-all.sh
# 启停 Master
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop master-server
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start master-server
# 启停 Worker
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start worker-server
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop worker-server
# 启停 Api
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start api-server
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop api-server
# 启停 Logger
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start logger-server
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop logger-server
# 启停 Alert
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start alert-server
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop alert-server
# 启停 Python Gateway
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh start python-gateway-server
sh /usr/local/dolphinscheduler-3.1.4/bin/dolphinscheduler-daemon.sh stop python-gateway-server
注意:
每个服务在路径
/conf/dolphinscheduler_env.sh 中都有 dolphinscheduler_env.sh 文件,这是可以为微 服务需求提供便利。意味着您可以基于不同的环境变量来启动各个服务,只需要在对应服务中配置 /conf/dolphinscheduler_env.sh 然后通过 /bin/start.sh 命令启动即可。但是如果您使用命令 /bin/dolphinscheduler-daemon.sh start 启动服务器,它将会用文件 bin/env/dolphinscheduler_env.sh 覆盖 /conf/dolphinscheduler_env.sh 然后启动服务,目的是为了减少用户修改配置的成本. 服务用途请具体参见《系统架构设计》小节。Python gateway service 默认与 api-server 一起启动,如果您不想启动 Python gateway service 请通过更改 api-server 配置文件 api-server/conf/application.yaml 中的 python-gateway.enabled : false 来禁用它。
3.11 登录 DolphinScheduler
浏览器访问地址 http://master:12345/dolphinscheduler/ui 即可登录系统UI。
默认的用户名和密码是 :
| 默认用户 | 默认密码 |
|---|---|
| admin | dolphinscheduler123 |

登录如下图所示:

去监控中心查看Masters,如下图所示:

去监控中心查看workers,如下图所示:

到此为止,DolphinScheduler集群安装部署就完成了。
3.12 DolphinScheduler Web UI介绍

4. DolphinScheduler功能应用
4.1 项目管理
4.1.1 项目创建
点击顶部导航项目管理--->项目创建--->填写如下信息

4.1.2 项目进入-修改与删除

4.1.3 项目首页
在项目列表中—>点击项目名称链接—>进入项目首页—>如下图:

项目首页包含该项目的任务状态统计、流程状态统计、工作流定义统计。这几个指标的说明如下:
- 任务状态统计:在指定时间范围内,统计任务实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数。
- 流程状态统计:在指定时间范围内,统计工作流实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数。
- 工作流定义统计:统计用户创建的工作流定义及管理员授予该用户的工作流定义。
4.2 工作流定义
4.2.1 创建工作流定义
- 创建工作流执行需要的租户
租户就是
操作系统的实际用户(admin),ds需要租户来真正执行。

租户创建完成。
- 创建用户

注意: 创建租户不创建用户的话,后面运行工作流时,DolphinScheduler运行工作流报错
there is not any tenant suitable, please choo

创建完后切换到gxjzy用户,不使用admin管理员创建工作流:
| 用户 | 密码 |
|---|---|
| gxjzy | gxjzy123 |

以下操作都是以gxjzy这个用户为主
- 点击项目管理->工作流->工作流定义,进入工作流定义页面,点击
创建工作流按钮,进入工作流DAG编辑页面,如下图所示: -
工具栏中拖拽
到画板中,新增一个Shell任务,如下图所示: -
添加 Shell 任务的参数设置:
- 填写
节点名称,描述,脚本字段; 运行标志勾选正常,若勾选禁止执行,运行工作流不会执行该任务;- 选择
任务优先级:当 worker 线程数不足时,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行; - 选择
任务优先级:当 worker 线程数不足时,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行; - 资源(非必选):资源文件是资源中心->文件管理页面创建或上传的文件,如文件名为
test.sh,脚本中调用资源命令为sh test.sh。注意调用需要使用资源的全路径; - 自定义参数(非必填);
- 点击
确定按钮,保存任务设置。
- 填写
- 配置任务之间的依赖关系: 点击任务节点的右侧加号连接任务;如下图所示,任务 Node_B 和任务 Node_C 并行执行,当任务 Node_A 执行完,任务 Node_B、Node_C 会同时执行。






- 配置任务之间的依赖关系: 点击任务节点的右侧加号连接任务;如下图所示,任务 Node_B 和任务 Node_C 并行执行,当任务 Node_A 执行完,任务 Node_B、Node_C 会同时执行。
注:上图中Node_B和Node_C是根据Node_A创建方式创建即可,后续的不同类型的工作流的创建也不在一步一步创建。
-
保存工作流定义: 点击画布右上角的
保存按钮,弹出基本信息弹框,如下图所示,输入工作流定义名称,工作流定义描述,设置全局变量(选填,参考全局参数),点击确定按钮,工作流定义创建成功。其他类型任务,请参考官网 任务节点类型和参数设置。
- 执行策略
并行:如果对于同一个工作流定义,同时有多个工作流实例,则并行执行工作流实例。串行等待:如果对于同一个工作流定义,同时有多个工作流实例,则并行执行工作流实例。串行抛弃:如果对于同一个工作流定义,同时有多个工作流实例,则抛弃后生成的工作流实例并杀掉正在跑的实例。串行优先:如果对于同一个工作流定义,同时有多个工作流实例,则按照优先级串行执行工作流实例。
- 实时任务的依赖关系: 若DAG中包含了实时任务的组件,则实时任务的关联关系显示为
虚线,在执行工作流实例的时候会跳过实时任务的执行。 -
删除任务的依赖关系:进入DAG图中 ,选中连接线,点击右上角
删除图标,删除任务间的依赖关系。





4.2.2 工作流定义操作功能
-
点击项目管理->工作流->工作流定义,进入工作流定义页面,如下图所示
工作流定义列表的操作功能如下:
- 编辑: 只能编辑
下线的工作流定义。工作流DAG编辑同创建工作流定义。 -
上线: 工作流状态为
下线时,上线工作流,只有上线状态的工作流能运行,但不能编辑。 -
下线: 工作流状态为
上线时,下线工作流,下线状态的工作流可以编辑,但不能运行。 -
运行: 只有上线的工作流能运行。运行操作步骤见运行工作流
-
定时: 只有上线的工作流能设置定时,系统自动定时调度工作流运行。创建定时后的状态为”下线”,需在定时管理页面上线定时才生效。定时操作步骤见工作流定时
-
定时管理: 定时管理页面可编辑、上线/下线、删除定时。
-
删除: 删除工作流定义。在同一个项目中,只能删除自己创建的工作流定义,其他用户的工作流定义不能进行删除,如果需要删除请联系创建用户或者管理员。
-
下载: 下载工作流定义到本地。
-
树形图: 以树形结构展示任务节点的类型及任务状态,如下图所示:
- 编辑: 只能编辑


4.2.3 运行工作流
-
点击项目管理->工作流->工作流定义,进入工作流定义页面,如下图所示,点击
上线按钮,上线工作流。 -
点击
运行按钮,弹出启动参数设置弹框,如下图所示,设置启动参数,点击弹框中的运行按钮,工作流开始运行,工作流实例页面生成一条工作流实例。工作流运行参数说明:
- 失败策略:当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略。
继续表示:某一任务失败后,其他任务节点正常执行;结束表示:终止所有正在执行的任务,并终止整个流程。 -
通知策略:当流程结束,根据流程状态发送流程执行信息通知邮件,包含任何状态都不发,成功发,失败发,成功或失败都发。
-
流程优先级:流程运行的优先级,分五个等级:
最高(HIGHEST),高(HIGH),中(MEDIUM),低(LOW),最低(LOWEST)。当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。 -
Worker 分组:该流程只能在指定的 worker 机器组里执行。默认是 Default,可以在任一 worker 上执行。
-
通知组:选择通知策略||超时报警||发生容错时,会发送流程信息或邮件到通知组里的所有成员。
-
启动参数: 在启动新的流程实例时,设置或覆盖全局参数的值。
-
补数:指运行指定日期范围内的工作流定义,根据补数策略生成对应的工作流实例,补数策略包括串行补数、并行补数 2 种模式。
日期可以通过页面选择或者手动输入,日期范围是左关右关区间(startDate <= N <= endDate)
- 串行补数:指定时间范围内,从开始日期至结束日期依次执行补数,依次生成多条流程实例;点击运行工作流,选择串行补数模式:例如从
12月 1号到12月20号依次执行,依次在流程实例页面生成两条流程实例。调度日期手动输入,在弹出的输入框中输入如下即可:
2024-01-26 00:00:00,2024-01-26 00:00:00重跑后结果:
- 并行度:是指在并行补数的模式下,最多并行执行的实例数。例如同时执行7月6号到7月10号的工作流定义,并行度为2,那么流程实例为:
调度日期手动输入,在弹出的输入框中输入如下即可:
2024-01-26 00:00:00,2024-01-30 00:00:00依赖模式补数结果如下:
- 补数与定时配置的关系:
未配置定时或已配置定时并定时状态下线:根据所选的时间范围结合定时默认配置(每天0点)进行补数,比如该工作流调度日期为7月7号到7月10号,流程实例为:-
已配置定时并定时状态上线:根据所选的时间范围结合定时配置进行补数,比如该工作流调度日期为7月7号到7月10号,配置了定时(每日凌晨5点运行),流程实例为:定时配置好后,选择
定时管理:将工作流的定时
上线,如下图:
-
空跑
空跑状态:
任务实例状态:
:star: 但是,任务并没有真正执行。
- 失败策略:当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略。















4.2.4 单独运行任务
-
右键选中任务,点击”启动”按钮(只有已上线的任务才能点击运行)
-
弹出启动参数设置弹框,参数说明同运行工作流
注意:
节点执行类型的选择。


4.2.5 工作流定时
- 创建定时:点击项目管理->工作流->工作流定义,进入工作流定义页面,上线工作流,点击
定时按钮,弹出定时参数设置弹框,如下图所示: -
选择起止时间。在起止时间范围内,定时运行工作流;不在起止时间范围内,不再产生定时工作流实例。
-
添加一个每天5时执行一次的定时,如下图所示:
-
失败策略、通知策略、流程优先级、Worker 分组、通知组、收件人、抄送人同工作流运行参数。
-
点击
创建按钮,创建定时成功,此时定时状态为”下线“,定时需上线才生效。 -
定时上线:点击
定时管理按钮,进入定时管理页面,点击上线按钮,定时状态变为上线,如下图所示,工作流定时生效。 -
工作流定时上线状态




4.2.6 导出工作流
工作流定义列表,选中操作中的导出,如下图:

点击导出后,工作流文件将会被下载到电脑本地。


4.2.7 倒入工作流
点击项目管理->工作流->工作流定义,进入工作流定义页面,点击导入工作流按钮,导入本地工作流文件,工作流定义列表显示导入的工作流,状态为下线。


到此为止,工作流相关的操作就结束了。
工作流复制

复制完成的结果:

注意:
复制不包含上下线的状态。
4.3 工作流实例
4.3.1 查看工作流实例
- 点击项目管理->工作流->工作流实例,进入工作流实例页面,如下图所示:
-
点击工作流名称链接,进入DAG查看页面,查看任务执行状态,如下图所示。


4.3.2 查看任务日志
-
进入工作流实例页面,点击工作流名称,进入DAG查看页面,双击任务节点,如下图所示:
- 点击”查看日志”,弹出日志弹框就是任务日志信息,如下图所示。任务实例页面也可查看任务日志,参考任务查看日志。


4.3.3 查看任务历史记录
- 点击项目管理->工作流->工作流实例,进入工作流实例页面,点击工作流名称,进入工作流 DAG 页面;
- 双击任务节点,如下图所示,点击”查看历史”,跳转到任务实例页面,并展示该工作流实例运行的任务实例列表

4.3.4 查看运行参数
- 点击项目管理->工作流->工作流实例,进入工作流实例页面,点击工作流名称,进入工作流 DAG 页面;
- 点击左上角
查看变量,查看工作流实例的全局参数和局部参数;点击左上角启动参数,查看工作流实例的启动参数,如下图所示

4.3.5 工作流实例操作功能
点击项目管理->工作流->工作流实例,进入工作流实例页面,如下图所示:

- 编辑: 只能编辑
成功/失败/停止状态的流程。点击编辑按钮或工作流实例名称进入 DAG 编辑页面,编辑后点击保存按钮,弹出保存 DAG 弹框,如下图所示,修改流程定义信息,在弹框中勾选是否更新工作流定义,保存后则将实例修改的信息更新到工作流定义;若不勾选,则不更新工作流定义。 -
重跑: 重新执行已经终止的流程。
-
恢复失败: 针对失败的流程,可以执行恢复失败操作,从失败的节点开始执行。
-
停止: 对正在运行的流程进行停止操作,后台会先
killworker 进程,再执行kill -9操作。 -
暂停: 对正在运行的流程进行暂停操作,系统状态变为等待执行,会等待正在执行的任务结束,暂停下一个要执行的任务。
-
恢复暂停: 对暂停的流程恢复,直接从暂停的节点开始运行。
-
删除: 删除工作流实例及工作流实例下的任务实例。
-
甘特图: Gantt 图纵轴是某个工作流实例下的任务实例的拓扑排序,横轴是任务实例的运行时间。

4.4 spark 项目实践
题目来源:GZ033 大数据应用开发赛题第08套指标计算
本任务基于以下2、3、4小题完成,使用DolphinScheduler完成第2、3、4题任务代码的调度。工作流要求,使用shell输出“开始”作为工作流的第一个job(job1),2、3、4题任务为并行任务且它们依赖job1的完成(命名为job2、job3、job4),job2、job3、job4完成之后使用shell输出“结束”作为工作流的最后一个job(endjob),endjob依赖job2、job3、job4,并将最终任务调度完成后的工作流截图,将截图粘贴至客户端桌面
流程如下:
:one: 创建租户“test” 》:two: 创建用户”test” 》 :three: 登录“test”用户 》 :four: 资源中心 上传文件(scala jar包) 》 :five: 创建项目 》:six:工作流定义 》:seven:项目上线运行
这里从:four:开始做演示:
:four:进入资源中心,上传jar包



上传后如下:

:five: 创建项目后进入项目


:six:工作流定义

job1:


job2:



参数:
--conf spark.driver.extraJavaOptions=-Dfile.encoding=UTF-8

job3 job4操作如job2 一致:
添加后如下:

endjob:


最终结果如下:

保存退出:

:seven:项目上线运行

运行项目:


运行后打开工作流实例查看运行状态:

等待片刻后,运行成功:

点击进入工作流实例,可以看到全部运行成功:

右键可查运行看日志:

查看运行日志:

完成
4.5 数据源中心
- MySQL
- PostgreSQL
- HIVE
- Spark
- Amazon Athena
- ClickHouse
- 等等….
4.5.1 MySQL数据源
点击顶部导航数据源中心--->创建数据源--->数据源选择MySQL--->填写如下信息--->测试连接--->成功--->确定

- 数据源:选择 MYSQL
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP 主机名:输入连接 MySQL 的 IP
- 端口:输入连接 MySQL 的端口
- 用户名:设置连接 MySQL 的用户名\
- 密码:设置连接 MySQL 的密码
- 数据库名:输入连接 MySQL 的数据库名称
- jdbc 连接参数:用于 MySQL 连接的参数设置,以 JSON 形式填写
注意:
数据源中心支持列出、查看、修改、删除等操作。
4.5.2 Hive数据源
点击顶部导航数据源中心--->创建数据源--->数据源选择HIVE/UMPALA--->写如下信息--->测试连接--->成功--->确定

- 数据源:选择 HIVE/IMPALA
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP 主机名:输入连接 HIVE 的 IP
- 端口:输入连接 HIVE 的端口,一般是hiveserver2,默认端口10000
- 用户名:设置连接 HIVE 的用户名,默认是系统的登录用户的用户名
- 密码:设置连接 HIVE 的密码,与系统登录用户匹配的密码
- 数据库名:输入连接 HIVE 的数据库名称(如果数据库不存在则报错) 连接
default库进行测试 - Jdbc 连接参数:用于 HIVE 连接的参数设置,以 JSON 形式填写
注意:如果您希望在同一个会话中执行多个 HIVE SQL,您可以修改配置文件 common.properties 中的配置,设置 support.hive.oneSession = true。 这对运行 HIVE SQL 前设置环境变量的场景会很有帮助。参数 support.hive.oneSession 默认值为 false,多条 SQL 将在不同的会话中运行。
4.5.3 spark数据源
点击顶部导航数据源中心--->创建数据源--->数据源选择SPARK--->写如下信息--->测试连接--->成功--->确定

- 数据源:选择 Spark
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接Spark的IP
- 端口:输入连接Spark的端口
- 用户名:设置连接Spark的用户名
- 密码:设置连接Spark的密码
- 数据库名:输入连接Spark的数据库名称(默认库default)
- Jdbc连接参数:用于Spark连接的参数设置,以JSON形式填写
注意:如果开启了kerberos,则需要填写 Principal
4.5.4 Clickhouse数据源
点击顶部导航数据源中心--->创建数据源--->数据源选择SPARK--->写如下信息--->测试连接--->成功--->确定

- 数据源:选择 clickhouse
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接clickhouse的IP
- 端口:输入连接clickhousek的端口,默认远程连接端口
8123 - 用户名:设置连接clickhouse的用户名(defaul)
- 密码:设置连接clickhouse的密码
- 数据库名:输入连接clickhouse的数据库名称(默认库default)
- Jdbc连接参数:用于Spark连接的参数设置,以JSON形式填写
待整理….
参考文档:https://blog.csdn.net/u010839779/article/details/130522432?spm=1001.2014.3001.5506